| | |
| --- | ---------------------------------- |
| $T$ | the target gas consumed per second |
| $M$ | minimum gas price |
| $K$ | gas price update constant |
| $C$ | maximum gas capacity |
| $R$ | gas capacity added per second |
### Making $T$ Dynamic
As noted above, the gas price determination mechanism relies on a target gas consumption per second, $T$, in order to calculate the gas price for a given block. $T$ will be adjusted dynamically according to the following specification.
Let $q$ be a non-negative integer that is initialized to 0 upon activation of this mechanism. Let the target gas consumption per second be expressed as:
$T = P \cdot e^{\frac{q}{D}}$
where $P$ is the global minimum allowed target gas consumption rate for the network, and $D$ is a constant that helps control the rate of change of the target gas consumption.
After the execution of transactions in block $b$, the value of $q$ can be increased or decreased up to $Q$. It must be the case that $\left|\Delta q\right| \leq Q$, or block $b$ is considered invalid. The amount by which $q$ changes after executing block $b$ is specified by the block builder.
Block builders (i.e. validators), may set their desired value for $T$ (i.e. their desired gas consumption rate) in their configuration, and their desired value for $q$ can then be calculated as:
$q_{desired} = D \cdot ln\left(\frac{T_{desired}}{P}\right)$
Note that since $q_{desired}$ is only used locally and can be different for each node, it is safe for implementations to approximate the value of $ln\left(\frac{T_{desired}}{P}\right)$, and round the resulting value to the nearest integer.
When building a block, builders can calculate their next preferred value for $q$ based on the network's current value (`q_current`) according to:
```python
# Calculates a node's new desired value for q given for a given block
def calc_next_q(q_current: int, q_desired: int, max_change: int) -> int:
if q_desired > q_current:
return q_current + min(q_desired - q_current, max_change)
else:
return q_current - min(q_current - q_desired, max_change)
```
As $q$ is updated after the execution of transactions within the block, $T$ is also updated such that $T = P \cdot e^{\frac{q}{D}}$ at all times. As the value of $T$ adjusts, the value of $R$ (capacity added per second) is also updated such that:
$R = 2 \cdot T$
This ensures that the gas price can increase and decrease at the same rate.
The value of $C$ must also adjust proportionately, so we set:
$C = 10 \cdot T$
This means that the maximum stored gas capacity would be reached after 5 seconds where no blocks have been accepted.
In order to keep roughly constant the time it takes for the gas price to double at sustained maximum network capacity usage, the value of $K$ used in the gas price determination mechanism must be updated proportionally to $T$ such that:
$K = 87 \cdot T$
In order to have the gas price not be directly impacted by the change in $K$, we also update $x$ (excess gas consumption) proportionally. When updating $x$ after executing a block, instead of setting $x = x + G$ as specified in ACP-103, we set:
$x_{n+1} = (x + G) \cdot \frac{K_{n+1}}{K_{n}}$
Note that the value of $q$ (and thus also $T$, $R$, $C$, $K$, and $x$) are updated **after** the execution of block $b$, which means they only take effect in determining the gas price of block $b+1$. The change to each of these values in block $b$ does not effect the gas price for transactions included in block $b$ itself.
Allowing block builders to adjust the target gas consumption rate in blocks that they produce makes it such that the effective target gas consumption rate should converge over time to the point where 50% of the voting stake weight wants it increased and 50% of the voting stake weight wants it decreased. This is because the number of blocks each validator produces is proportional to their stake weight.
As noted in ACP-103, the maximum gas consumed in a given period of time $\Delta{t}$, is $r + R \cdot \Delta{t}$, where $r$ is the remaining gas capacity at the end of previous block execution. The upper bound across all $\Delta{t}$ is $C + R \cdot \Delta{t}$. Phrased differently, the maximum amount of gas that can be consumed by any given block $b$ is:
$gasLimit_{b} = min(r + R \cdot \Delta{t}, C)$
### Configuration Parameters
As noted above, the gas price determination mechanism depends on the values of $T$, $M$, $K$, $C$, and $R$ to be set as parameters. $T$ is adjusted dynamically from its initial value based on $D$ and $P$, and the values of $R$ and $C$ are derived from $T$.
Parameters at activation on the C-Chain are:
| Parameter | Description | C-Chain Configuration |
| --------- | ------------------------------------------------------ | --------------------- |
| $P$ | minimum target gas consumption per second | $1,000,000$ |
| $D$ | target gas consumption rate update constant | $2^{25}$ |
| $Q$ | target gas consumption rate update factor change limit | $2^{15}$ |
| $M$ | minimum gas price | $1*10^{-18}$ AVAX |
| $K$ | initial gas price update factor | $87,000,000$ |
$P$ was chosen as a safe bound on the minimum target gas usage on the C-Chain. The current gas target of the C-Chain is $1,500,000$ per second. The target gas consumption rate will only stay at $P$ if the majority of stake weight of the network specifies $P$ as their desired gas consumption rate target.
$D$ and $Q$ were chosen to give each block builder the ability to adjust the value of $T$ by roughly $\frac{1}{1024}$ of its current value, which matches the [gas limit bound divisor that Ethereum currently uses](https://github.com/ethereum/go-ethereum/blob/52766bedb9316cd6cddacbb282809e3bdfba143e/params/protocol_params.go#L26) to limit the amount that validators can change the execution layer gas limit in a single block. $D$ and $Q$ were scaled up by a factor of $2^{15}$ to provide block builders more granularity in the adjustments to $T$ that they can make.
$M$ was chosen as the minimum possible denomination of the native EVM asset, such that the gas price will be more likely to consistently be in a range of price discovery. The price discovery mechanism has already been battle tested on the P-Chain (and prior to that on Ethereum for blob gas prices as defined by EIP-4844), giving confidence that it will correctly react to any increase in network usage in order to prevent a DOS attack.
$K$ was chosen such that at sustained maximum capacity ($T*2$ gas/second), the fee rate will double every \~60.3 seconds. For comparison, EIP-1559 can double about \~70 seconds, and the C-Chain's current implementation can double about every \~50 seconds, depending on the time between blocks.
The maximum instantaneous price multiplier is:
$e^\frac{C}{K} = e^\frac{10 \cdot T}{87 \cdot T} = e^\frac{10}{87} \simeq 1.12$
### Choosing $T_{desired}$
As mentioned above, this new mechanism allows for validators to specify their desired target gas consumption rate ($T_{desired}$) in their configuration, and the value that they set impacts the effective target gas consumption rate of the network over time. The higher the value of $T$, the more resources (storage, compute, etc) that are able to be used by the network. When choosing what value makes sense for them, validators should consider the resources that are required to properly support that level of gas consumption, the utility the network provides by having higher transaction per second throughput, and the stability of network should it reach that level of utilization.
While Avalanche Network Clients can set default configuration values for the desired target gas consumption rate, each validator can choose to set this value independently based on their own considerations.
## Backwards Compatibility
The changes proposed in this ACP require a required network upgrade in order to take effect. Prior to its activation, the current gas limit and price discovery mechanisms will continue to be used. Its activation should have relatively minor compatibility effects on any developer tooling. Notably, transaction formats, and thus wallets, are not impacted. After its activation, given that the value of $C$ is dynamically adjusted, the maximum possible gas consumed by an individual block, and thus maximum possible consumed by an individual transaction, will also dynamically adjust. The upper bound on the amount of gas consumed by a single transaction fluctuating means that transactions that are considered invalid at one time may be considered valid at a different point in time, and vice versa. While potentially unintuitive, as long as the minimum gas consumption rate is set sufficiently high this should not have significant practical impact, and is also currently the case on the Ethereum mainnet.
> \[!NOTE]
> After the activation of this ACP, concerns were raised around the latency of inclusion for large transactions when the fee is increasing. To address these concerns, block producers SHOULD only produce blocks when there is sufficient capacity to include large transactions. Prior to this ACP, the maximum size of a transaction was $15$ million gas. Therefore, the recommended heuristic is to only produce blocks when there is at least $\min(8 \cdot T, 15 \text{ million})$ capacity. *At the time of writing, this ensures transactions with up to 12.8 million gas will be able to bid for block space.*
## Reference Implementation
This ACP was implemented and merged into Coreth behind the `Fortuna` upgrade flag. The full implementation can be found in [coreth@v0.14.1-acp-176.1](https://github.com/ava-labs/coreth/releases/tag/v0.14.1-acp-176.1).
## Security Considerations
This ACP changes the mechanism for determining the gas price on Avalanche EVM chains. The gas price is meant to adapt dynamically to respond to changes in demand for using the chain. If it does not react as expected, the chain could be at risk for a DOS attack (if the usage price is too low), or over charge users during period of low activity. This price discovery mechanism has already been employed on the P-Chain, but should again be thoroughly tested for use on the C-Chain prior to activation on the Avalanche Mainnet.
Further, this ACP also introduces a mechanism for validators to change the gas limit of the C-Chain. If this limit is set too high, it is possible that validator nodes will not be able to keep up in the processing of blocks. An upper bound on the maximum possible gas limit could be considered to try to mitigate this risk, though it would then take further required network upgrades to scale the network past that limit.
## Acknowledgments
Thanks to the following non-exhaustive list of individuals for input, discussion, and feedback on this ACP.
* [Emin Gün Sirer](https://x.com/el33th4xor)
* [Luigi D'Onorio DeMeo](https://x.com/luigidemeo)
* [Darioush Jalali](https://github.com/darioush)
* [Aaron Buchwald](https://github.com/aaronbuchwald)
* [Geoff Stuart](https://github.com/geoff-vball)
* [Meag FitzGerald](https://github.com/meaghanfitzgerald)
* [Austin Larson](https://github.com/alarso16)
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-181: P Chain Epoched Views
URL: /docs/acps/181-p-chain-epoched-views
Details for Avalanche Community Proposal 181: P Chain Epoched Views
| ACP | 181 |
| :------------ | :----------------------------------------------------------------------------------------- |
| **Title** | P-Chain Epoched Views |
| **Author(s)** | Cam Schultz [@cam-schultz](https://github.com/cam-schultz) |
| **Status** | Implementable ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/211)) |
| **Track** | Standards |
## Abstract
Proposes a standard P-Chain epoching scheme such that any VM that implements it uses a P-Chain block height known prior to the generation of its next block. This would enable VMs to optimize validator set retrievals, which currently must be done during block execution. This standard does *not* introduce epochs to the P-Chain's VM directly. Instead, it provides a standard that may be implemented by layers that inject P-Chain state into VMs, such as the ProposerVM.
## Motivation
The P-Chain maintains a registry of L1 and Subnet validators (including Primary Network validators). Validators are added, removed, or their weights changed by issuing P-Chain transactions that are included in P-Chain blocks. When describing an L1 or Subnet's validator set, what is really being described are the weights, BLS keys, and Node IDs of the active validators at a particular P-Chain height. Use cases that require on-demand views of L1 or Subnet validator sets need to fetch validator sets at arbitrary P-Chain heights, while use cases that require up-to-date views need to fetch them as often as every P-Chain block.
Epochs during which the P-Chain height is fixed would widen this window to a predictable epoch duration, allowing these use cases to implement optimizations such as pre-fetching validator sets once per epoch, or allowing more efficient backwards traversal of the P-Chain to fetch historical validator sets.
## Specification
### Assumptions
In the following specification, we assume that a block $b_m$ has timestamp $t_m$ and P-Chain height $p_m$.
### Epoch Definition
An epoch is defined as a contiguous range of blocks that share the same three values:
* An Epoch Number
* An Epoch P-Chain Height
* An Epoch Start Time
Let $E_N$ denote an epoch with epoch number $N$. $E_N$'s start time is denoted as $T_{start}^N$, and its P-Chain height as $P_N$.
Let block $b_a$ be the block that activates this ACP. The first epoch ($E_0$) has $T_{start}^0 = t_{a-1}$, and $P_0 = p_{a-1}$. In other words, the first epoch start time is the timestamp of the last block prior to the activation of this ACP, and similarly, the first epoch P-Chain height is the P-Chain height of last block prior to the activation of this ACP.
### Epoch Sealing
An epoch $E_N$ is *sealed* by the first block with a timestamp greater than or equal to $T_{start}^N + D$, where $D$ is a constant defined in the network upgrade that activates this ACP. Let $B_{S_N}$ denote the block that sealed $E_N$.
The sealing block is defined to be a member of the epoch it seals. This guarantees that every epoch will contain at least one block.
### Advancing an Epoch
We advance from the current epoch $E_N$ to the next epoch $E_{N+1}$ when the next block after $B_{S_N}$ is produced. This block will be a member of $E_{N+1}$, and will have the values:
* $P_{N+1}$ equal to the P-Chain height of $B_{S_N}$
* $T_{start}^{N+1}$ equal to $B_{S_N}$'s timestamp
* The epoch number, $N+1$ increments the previous epoch's epoch number by exactly $1$
## Properties
### Epoch Duration Bounds
Since an epoch's start time is set to the [timestamp of the sealing block of the previous epoch](#advancing-an-epoch), all epochs are guaranteed to have a duration of at least $D$, as measured from the epoch's starting time to the timestamp of the epoch's sealing block. However, since a sealing block is [defined](#epoch-sealing) to be a member of the epoch it seals, there is no upper bound on an epoch's duration, since that sealing block may be produced at any point in the future beyond $T_{start}^N + D$.
### Fixing the P-Chain Height
When building a block, Avalanche blockchains use the P-Chain height [embedded in the block](#assumptions) to determine the validator set. If instead the epoch P-Chain height is used, then we can ensure that when a block is built, the validator set to be used for the next block is known. To see this, suppose block $b_m$ seals epoch $E_N$. Then the next block, $b_{m+1}$ will begin a new epoch, $E_{N+1}$ with $P_{N+1}$ equal to $b_m$'s P-Chain height, $p_m$. If instead $b_m$ does not seal $E_N$, then $b_{m+1}$ will continue to use $P_{N}$. Both candidates for $b_{m+1}$'s P-Chain height ($p_m$ and $P_N$) are known at $b_m$ build time.
## Use Cases
### ICM Verification Optimization
For a validator to verify an ICM message, the signing L1/Subnet's validator set must be retrieved during block execution by traversing backward from the current P-Chain height to the P-Chain height provided by the ProposerVM. The traversal depth is highly variable, so to account for the worst case, VM implementations charge a large fixed amount of gas to perform this verification.
With epochs, validator set retrieval occurs at fixed P-Chain heights that increment at regular intervals, which provides opportunities to optimize this retrieval. For instance, validator retrieval may be done asynchronously from block execution as soon as $D$ time has passed since the current epoch's start time, allowing the verification gas cost to be safely reduced by a significant amount.
### Improved Relayer Reliability
Current ICM VM implementations verify ICM messages against the local P-Chain state, as determined by the P-Chain height set by the ProposerVM. Off-chain relayers perform the following steps to deliver ICM messages:
1. Fetch the sending chain's validator set at the verifying chain's current proposed height
2. Collect BLS signatures from that validator set to construct the signed ICM message
3. Submit the transaction containing the signed message to the verifying chain
If the validator set changes between steps 1 and 3, the ICM message will fail verification.
Epochs improve upon this by fixing the P-Chain height used to verify ICM messages for a duration of time that is predictable to off-chain relayers. A relayer should be able to derive the epoch boundaries based on the specification above, or they could retrieve that information via a node API. Relayers could use that information to decide the validator set to query, knowing that it will be stable for the duration of the epoch. Further, VMs could relax the verification rules to allow ICM messages to be verified against the previous epoch as a fallback, eliminating edge cases around the epoch boundary.
## Backwards Compatibility
This change requires a network upgrade and is therefore not backwards compatible.
Any downstream entities that depend on a VM's view of the P-Chain will also need to account for epoched P-Chain views. For instance, ICM messages are signed by an L1's validator set at a specific P-Chain height. Currently, the constructor of the signed message can in practice use the validator set at the P-Chain tip, since all deployed Avalanche VMs are at most behind the P-Chain by a fixed number of blocks. With epoching, however, the ICM message constructor must take into account the epoch P-Chain height of the verifying chain, which may be arbitrarily far behind the P-Chain tip.
## Reference Implementation
The following pseudocode illustrates how an epoch may be calculated for a block:
```go
// Epoch Duration
const D time.Duration
type Epoch struct {
PChainHeight uint64
Number uint64
StartTime time.Time
}
type Block interface {
Timestamp() time.Time
PChainHeight() uint64
Epoch() Epoch
}
func GetPChainEpoch(parent Block) Epoch {
parentTimestamp := parent.Timestamp()
parentEpoch := parent.Epoch()
epochEndTime := parentEpoch.StartTime.Add(D)
if parentTimestamp.Before(epochEndTime) {
// If the parent was issued before the end of its epoch, then it did not
// seal the epoch.
return parentEpoch
}
// The parent sealed the epoch, so the child is the first block of the new
// epoch.
return Epoch{
PChainHeight: parent.PChainHeight(),
Number: parentEpoch.Number + 1,
StartTime: parentTimestamp,
}
}
```
* If the parent sealed its epoch, the current block [advances the epoch](#advancing-an-epoch), refreshing the epoch height, incrementing the epoch number, and setting the epoch starting time.
* Otherwise, the current block uses the current epoch height, number, and starting time, regardless of whether it seals the epoch.
A full reference implementation of this ACP for avalanchego can be found [here](https://github.com/ava-labs/avalanchego/pull/4238).
### Setting the Epoch Duration
The epoch duration $D$ is set on a network-wide level. For both Fuji (network ID 5) and Mainnet (network ID 1), $D$ will be set to 5 minutes upon activation of this ACP. Any changes to $D$ in the future would require another network upgrade.
#### Changing the Epoch Duration
Future network upgrades may change the value of $D$ to some new duration $D'$. $D'$ should not take effect until the end of the current epoch, rather than the activation time of the network upgrade that defines $D'$. This ensures an in progress epoch at the upgrade activation time cannot have a realized duration less than both $D$ and $D'$.
## Security Considerations
### Epoch P-Chain Height Skew
Because epochs may have [unbounded duration](#epoch-duration-bounds), it is possible for a block's `PChainEpochHeight` to be arbitrarily far behind the tip of the P-Chain. This does not affect the *validity* of ICM verification within a VM that implements P-Chain epoched views, since the validator set at `PChainEpochHeight` is always known. However, the following considerations should be made under this scenario:
1. As validators exit the validator set, their physical nodes may be unavailable to serve BLS signature requests, making it more difficult to construct a valid ICM message
2. A valid ICM message may represent an attestation by a stale validator set. Signatures from validators that have exited the validator set between `PChainEpochHeight` and the current P-Chain tip will not represent active stake.
Both of these scenarios may be mitigated by having shorter epoch lengths, which limit the delay in time between when the P-Chain is updated and when those updates are taken into account for ICM verification on a given L1, and by ensuring consistent block production, so that epochs always advance soon after $D$ time has passed.
### Excessive Validator Churn
If an epoched view of the P-Chain is used by the consensus engine, then validator set changes over an epoch's duration will be concentrated into a single block at the epoch's boundary. Excessive validator churn can cause consensus failures and other dangerous behavior, so it is imperative that the amount of validator weight change at the epoch boundary is limited. One strategy to accomplish this is to queue validator set changes and spread them out over multiple epochs. Another strategy is to batch updates to the same validator together such that increases and decreases to that validator's weight cancel each other out. Given the primary use case of ICM verification improvements, which occur at the VM level, mechanisms to mitigate against this are omitted from this ACP.
## Open Questions
* What should the epoch duration $D$ be set to?
* Is it safe for `PChainEpochHeight` and `PChainHeight` to differ significantly within a block, due to [unbounded epoch duration](#epoch-duration-bounds)?
## Acknowledgements
Thanks to [@iansuvak](https://github.com/iansuvak), [@geoff-vball](https://github.com/geoff-vball), [@yacovm](https://github.com/yacovm), [@michaelkaplan13](https://github.com/michaelkaplan13), [@StephenButtolph](https://github.com/StephenButtolph), and [@aaronbuchwald](https://github.com/aaronbuchwald) for discussion and feedback on this ACP.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-191: Seamless L1 Creation
URL: /docs/acps/191-seamless-l1-creation
Details for Avalanche Community Proposal 191: Seamless L1 Creation
| ACP | 191 |
| :------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Title** | Seamless L1 Creations (CreateL1Tx) |
| **Author(s)** | Martin Eckardt ([@martineckardt](https://github.com/martineckardt)), Aaron Buchwald ([@aaronbuchwald](https://github.com/aaronbuchwald)), Michael Kaplan ([@michaelkaplan13](https://github.com/michaelkaplan13)), Meaghan FitzGerald ([@meaghanfitzgerald](https://github.com/meaghanfitzgerald)) |
| **Status** | Proposed ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/197)) |
| **Track** | Standards |
## Abstract
This ACP introduces a new P-Chain transaction type called `CreateL1Tx` that simplifies the creation of Avalanche L1s. It consolidates three existing transaction types (`CreateSubnetTx`, `CreateChainTx`, and `ConvertSubnetToL1Tx`) into a single atomic operation. This streamlines the L1 creation process, removes the need for the intermediary Subnet creation step, and eliminates the management of temporary `SubnetAuth` credentials.
## Motivation
[ACP-77](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/77-reinventing-subnets/README.md) introduced Avalanche L1s, providing greater sovereignty and flexibility compared to Subnets. However, creating an L1 currently requires a three-step process:
1. `CreateSubnetTx`: Create the Subnet record on the P-Chain and specify the `SubnetAuth`
2. `CreateChainTx`: Add a blockchain to the Subnet (can be called multiple times)
3. `ConvertSubnetToL1Tx`: Convert the Subnet to an L1, specifying the initial validator set and the validator manager location
This process has several drawbacks:
* It requires orchestrating three separate transactions that could be handled in one.
* The `SubnetAuth` must be managed during creation but becomes irrelevant after conversion.
* The multi-step process increases complexity and potential for errors.
* It introduces unnecessary state transitions and storage overhead on the P-Chain.
By introducing a single `CreateL1Tx` transaction, we can simplify the process, reduce overhead, and improve the developer experience for creating L1s.
## Specification
### New Transaction Type
The following new transaction type is introduced:
```go
// ChainConfig represents the configuration for a chain to be created
type ChainConfig struct {
// A human readable name for the chain; need not be unique
ChainName string `serialize:"true" json:"chainName"`
// ID of the VM running on the chain
VMID ids.ID `serialize:"true" json:"vmID"`
// IDs of the feature extensions running on the chain
FxIDs []ids.ID `serialize:"true" json:"fxIDs"`
// Byte representation of genesis state of the chain
GenesisData []byte `serialize:"true" json:"genesisData"`
}
// CreateL1Tx is an unsigned transaction to create a new L1 with one or more chains
type CreateL1Tx struct {
// Metadata, inputs and outputs
BaseTx `serialize:"true"`
// Chain configurations for the L1 (can be multiple)
Chains []ChainConfig `serialize:"true" json:"chains"`
// Chain where the L1 validator manager lives
ManagerChainID ids.ID `serialize:"true" json:"managerChainID"`
// Address of the L1 validator manager
ManagerAddress types.JSONByteSlice `serialize:"true" json:"managerAddress"`
// Initial pay-as-you-go validators for the L1
Validators []*L1Validator `serialize:"true" json:"validators"`
}
```
The `L1Validator` structure follows the same definition as in [ACP-77](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/77-reinventing-subnets/README.md#convertsubnettol1tx).
### Transaction Processing
When a `CreateL1Tx` transaction is processed, the P-Chain performs the following operations atomically:
1. Create a new L1.
2. Create chain records for each chain configuration in the `Chains` array.
3. Set up the L1 validator manager with the specified `ManagerChainID` and `ManagerAddress`.
4. Register the initial validators specified in the `Validators` array.
### IDs
* `subnetID`: The `subnetID` of the L1 is the transaction hash.
* `blockchainID`: the `blockchainID` for each blockchain is is defined as the SHA256 hash of the 37 bytes resulting from concatenating the 32 byte `subnetID` with the `0x00` byte and the 4 byte `chainIndex` (index in the `Chains` array within the transaction)
* `validationID`: The `validationID` for the initial validators added through `CreateL1Tx` is defined as the SHA256 hash of the 36 bytes resulting from concatenating the 32 byte `subnetID` with the 4 byte `validatorIndex` (index in the `Validators` array within the transaction).
Note: Even with this updated definition of the `blockchainID`s for chains created using this new flow, the `validationID`s of the L1s initial set of validators is still compatible with the existing reference validator manager contracts as defined [here](https://github.com/ava-labs/icm-contracts/blob/4a897ba913958def3f09504338a1b9cd48fe5b2d/contracts/validator-manager/ValidatorManager.sol#L247).
### Restrictions and Validation
The `CreateL1Tx` transaction has the following restrictions and validation criteria:
1. The `Chains` array must contain at least one chain configuration
2. The `ManagerChainID` must be a valid blockchain ID, but cannot be the P-Chain blockchain ID
3. Validator nodes must have unique NodeIDs within the transaction
4. Each validator must have a non-zero weight and a non-zero balance
5. The transaction inputs must provide sufficient AVAX to cover the transaction fee and all validator balances
### Warp Message
After the transaction is accepted, the P-Chain must be willing to sign a `SubnetToL1ConversionMessage` with a `conversionID` corresponding to the new L1, similar to what would happen after a `ConvertSubnetToL1Tx`. This ensures compatibility with existing systems that expect this message, such as the validator manager contracts.
## Backwards Compatibility
This ACP introduces a new transaction type and does not modify the behavior of existing transaction types. Existing Subnets and L1s created through the three-step process will continue to function as before. This change is purely additive and does not require any changes to existing L1s or Subnets.
The existing transactions `CreateSubnetTx`, `CreateChainTx` and `ConvertSubnetToL1Tx` remain unchanged for now, but may be removed in a future ACP to ensure systems have sufficient time to update to the new process.
## Reference Implementation
A reference implementation must be provided in order for this ACP to be considered implementable.
## Security Considerations
The `CreateL1Tx` transaction follows the same security model as the existing three-step process. By making the L1 creation atomic, it reduces the risk of partial state transitions that could occur if one of the transactions in the three-step process fails.
The same continuous fee mechanism introduced in ACP-77 applies to L1s created through this new transaction type, ensuring proper metering of validator resources.
The transaction verification process must ensure that all validator properties are properly validated, including unique NodeIDs, valid BLS signatures, and sufficient balances.
## Rationale and Alternatives
The primary alternative is to maintain the status quo - requiring three separate transactions to create an L1. However, this approach has clear disadvantages in terms of complexity, transaction overhead, and user experience.
Another alternative would be to modify the existing `ConvertSubnetToL1Tx` to allow specifying chain configurations directly. However, this would complicate the conversion process for existing Subnets and would not fully address the desire to eliminate the Subnet intermediary step for new L1 creation.
The chosen approach of introducing a new transaction type provides a clean solution that addresses all identified issues while maintaining backward compatibility.
## Acknowledgements
The idea for this PR was originally formulated by Aaron Buchwald in our discussion about the creation of L1s. Special thanks to the authors of ACP-77 for their groundbreaking work on Avalanche L1s, and to the projects that have shared their experiences and challenges with the current validator manager framework.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-194: Streaming Asynchronous Execution
URL: /docs/acps/194-streaming-asynchronous-execution
Details for Avalanche Community Proposal 194: Streaming Asynchronous Execution
| ACP | 194 |
| :------------ | :------------------------------------------------------------------------------------------------------------------------------- |
| **Title** | Streaming Asynchronous Execution |
| **Author(s)** | Arran Schlosberg ([@ARR4N](https://github.com/ARR4N)), Stephen Buttolph ([@StephenButtolph](https://github.com/StephenButtolph)) |
| **Status** | Proposed ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/196)) |
| **Track** | Standards |
## Abstract
Streaming Asynchronous Execution (SAE) decouples consensus and execution by introducing a queue upon which consensus is performed.
A concurrent execution stream is responsible for clearing the queue and reporting a delayed state root for recording by later rounds of consensus.
Validation of transactions to be pushed to the queue is lightweight but guarantees eventual execution.
## Motivation
### Performance improvements
1. Concurrent consensus and execution streams eliminate node context switching, reducing latency caused by each waiting on the other.
In particular, "VM time" (akin to CPU time) more closely aligns with wall time since it is no longer eroded by consensus.
This increases gas per wall-second even without an increase in gas per VM-second.
2. Lean, execution-only clients can rapidly execute the queue agreed upon by consensus, providing accelerated receipt issuance and state computation.
Without the need to compute state *roots*, such clients can eschew expensive Merkle data structures.
End users see expedited but identical transaction results.
3. Irregular stop-the-world events like database compaction are amortised over multiple blocks.
4. Introduces additional bursty throughput by eagerly accepting transactions, without a reduction in security guarantees.
5. Third-party accounting of non-data-dependent transactions, such as EOA-to-EOA transfers of value, can be performed prior to execution.
### Future features
Performing transaction execution after consensus sequencing allows the usage of consensus artifacts in execution. This unblocks some additional future improvements:
1. Exposing a real-time VRF during transaction execution.
2. Using an encrypted mempool to reduce front-running.
This ACP does not introduce these, but some form of asynchronous execution is required to correctly implement them.
### User stories
1. A sophisticated DeFi trader runs a highly optimised execution client, locally clearing the transaction queue well in advance of the network—setting the stage for HFT DeFi.
2. A custodial platform filters the queue for only those transactions sent to one of their EOAs, immediately crediting user balances.
## Description
In all execution models, a block is *proposed* and then verified by validators before being *accepted*. To assess a block's validity in *synchronous* execution, its transactions are first *executed* and only then *accepted* by consensus. This immediately and implicitly *settles* all of the block's transactions by including their execution results at the time of *acceptance*.
| | |
| --- | ---------------------------------- |
| $T$ | the target gas consumed per second |
| $M$ | minimum gas price |
| $K$ | gas price update constant |
| $R$ | gas capacity added per second |
ACP-176 provided a mechanism to make $T$ dynamic and set:
$$
\begin{align}
R &= 2 \cdot T \\
K &= 87 \cdot T
\end{align}
$$
The *excess* actual consumption $x \ge 0$ beyond the target $T$ is tracked via numerical integration and used to calculate the gas price as:
$M \cdot \exp\left(\frac{x}{K}\right)$
### Gas charged
We introduce $g_L$, $g_U$, and $g_C$ as the gas *limit*, *used*, and *charged* per transaction, respectively. We define
$$
g_C := \max\left(g_U, \frac{g_L}{\lambda}\right)
$$
where $\lambda$ enforces a lower bound on the gas charged based on the gas limit.
> \[!NOTE]
> $\dfrac{g_L}{\lambda}$ is rounded up by actually calculating $\dfrac{g_L + \lambda - 1}{\lambda}$
In all previous instances where execution referenced gas used, from now on, we will reference gas charged. For example, the gas excess $x$ will be modified by $g_C$ rather than $g_U$.
### Block size
The constant time delay between block execution and settlement is defined as $\tau$ seconds.
The maximum allowed size of a block is defined as:
$$
\omega_B ~:= R \cdot \tau \cdot \lambda
$$
Any block whose total sum of gas limits for transactions exceed $\omega_B$ MUST be considered invalid.
### Queue size
The maximum allowed size of the execution queue *prior* to adding a new block is defined as:
$$
\omega_Q ~:= 2 \cdot \omega_B
$$
Any block that attempts to be enqueued while the current size of the queue is larger than $\omega_Q$ MUST be considered invalid.
> \[!NOTE]
> By restricting the size of the queue *prior* to enqueueing the new block, $\omega_B$ is guaranteed to be the only limitation on block size.
### Block executor
During the activation of SAE, the block executor's timestamp $t_e$ is initialised to the timestamp of the last accepted block.
Prior to executing a block with timestamp $t_b$, the executor's timestamp and excess is updated:
$$
\begin{align}
\Delta{t} &~:= \max\left(0, t_b - t_e\right) \\
t_e &~:= t_e + \Delta{t} \\
x &~:= \max\left(x - T \cdot \Delta{t}, 0\right) \\
\end{align}
$$
The block is then executed with the gas price calculated from the current value of $x$.
After executing a block that charged $g_C$ gas in total, the executor's timestamp and excess is updated:
$$
\begin{align}
\Delta{t} &~:= \frac{g_C}{R} \\
t_e &~:= t_e + \Delta{t} \\
x &~:= x + \Delta{t} \cdot (R - T) \\
\end{align}
$$
> \[!NOTE]
> The update rule here assumes that $t_e$ is a timestamp that tracks the passage of time both by gas and by wall-clock time. $\frac{g_C}{R}$ MUST NOT be simply rounded. Rather, the gas accumulation MUST be left as a fraction.
$t_e$ is now this block's execution timestamp.
### Handling gas target changes
When a block is produced that modifies $T$, both the consensus thread and the execution thread will update to the modified $T$ after their own handling of the block.
For example, restrictions of the queue size MUST be calculated based on the parent block's $T$.
Similarly, the time spent executing a block MUST be calculated based on the parent block's $T$.
### Block settlement
For a *proposed* block that includes timestamp $t_b$, all ancestors whose execution timestamp $t_e$ is $t_e \leq t_b - \tau$ are considered settled.
Note that $t_e$ is not an integer as it tracks fractional seconds with gas consumption, which is not the case for $t_b$.
The *proposed* block MUST include the `stateRoot` produced by the execution of the most recently settled block.
For any *newly* settled blocks, the *proposed* block MUST include all execution artifacts:
* `receiptsRoot`
* `logsBloom`
* `gasUsed`
The receipts root MUST be computed as defined in [EIP-2718](https://eips.ethereum.org/EIPS/eip-2718) except that the tree MUST be built from the concatenation of receipts from all blocks being settled.
> \[!NOTE]
> If the block executor has fallen behind, the node may not be able to determine precisely which ancestors should be considered settled. If this occurs, validators MUST allow the block executor to catch up prior to deciding the block's validity.
### Block validity and building
After determining which blocks to settle, all remaining ancestors of the new block must be inspected to determine the worst-case bounds on $x$ and account balances. Account nonces are able to be known immediately.
The worst-case bound on $x$ can be calculated by following the block executor update rules using $g_L$ rather than $g_C$.
The worst-case bound on account balances can be calculated by charging the worst-case gas cost to the sender of a transaction along with deducting the value of the transaction from the sender's account balance.
The `baseFeePerGas` field MUST be populated with the gas price based on the worst-case bound on $x$ at the start of block execution.
### Configuration Parameters
As noted above, SAE depends on the values of $\tau$ and $\lambda$ to be set as parameters and the values of $\omega_B$ and $\omega_Q$ are derived from $T$.
Parameters to specify for the C-Chain are:
| Parameter | Description | C-Chain Configuration |
| --------- | ------------------------------------------------ | --------------------- |
| $\tau$ | duration between execution and settlement | $5s$ |
| $\lambda$ | minimum conversion from gas limit to gas charged | $2$ |
## Backwards Compatibility
This ACP modifies the meaning of multiple fields in the block. A comprehensive list of changes will be produced once a reference implementation is available.
Likely fields to change include:
* `stateRoot`
* `receiptsRoot`
* `logsBloom`
* `gasUsed`
* `extraData`
## Reference Implementation
A reference implementation is still a work-in-progress. This ACP will be updated to include a reference implementation once one is available.
## Security Considerations
### Worst-case transaction validity
To avoid a DoS vulnerability on execution, we require an upper bound on transaction gas cost (i.e. amount $\times$ price) beyond the regular requirements for transaction validity (e.g. nonce, signature, etc.). We therefore introduced "worst-case cost" validity.
We can prove that if every transaction were to use its full gas limit this would result in the greatest possible:
1. Consumption of gas units (by definition of the gas limit); and
2. Gas excess $x$ (and therefore gas price) at the time of execution.
For a queue of blocks $Q = \\{i\\}_ {i \ge 0}$ the gas excess $x_j$ immediately prior to execution of block $j \in Q$ is a monotonic, non-decreasing function of the gas usage of all preceding blocks in the queue; i.e. $x_j~:=~f(\\{g_i\\}_{i
| Parameter | Description | C-Chain Configuration |
| --------- | ---------------------------------------------- | --------------------- |
| $M$ | minimum `minimumBlockDelay` value | 1 millisecond |
| $q$ | initial `minimumBlockDelayExcess` | 7,970,124 |
| $D$ | `minimumBlockDelay` update constant | $2^{20}$ |
| $Q$ | `minimumBlockDelay` update factor change limit | 200 |
$M$ was chosen as a lower bound for `minimumBlockDelay` values to allow high-performance Avalanche L1s to be able to realize maximum performance and minimal transaction latency.
Based on the 1 millisecond value for $M$, $q$ was chosen such that the effective `minimumBlockDelay` value at time of activation is as close as possible to the current target block rate of the C-Chain, which is 2 seconds.
$D$ and $Q$ were chosen such that it takes approximately 3,600 consecutive blocks of the maximum allowed change in $q$ for the effective `minimumBlockDelay` value to either halve or double.
### ProposerVM `MinBlkDelay`
The ProposerVM currently offers a static, configurable `MinBlkDelay` seconds for consecutive blocks. With this ACP enforcing a dynamic minimum block delay time, any EVM instance adopting this ACP that also leverages the ProposerVM should ensure that the ProposerVM `MinBlkDelay` is set to 0.
### Note on Block Building
While there is no longer a requirement for blocks to burn a minimum block gas cost after the activation of this ACP, block builders should still take priority fees into account when building blocks to allow for transaction prioritization and to maximize the amount of native token (AVAX) burned in the block.
From a user (transaction issuer) perspective, this means that a non-zero priority fee would only ever need to be set to ensure inclusion during periods of maximum gas utilization.
## Backwards Compatibility
While this proposal requires a network upgrade and updates the EVM block header format, it does so in a way that tries to maintain as much backwards compatibility as possible. Specifically, applications that currently parse and use the existing timestamp field that is denominated in seconds can continue to do so. The `timestampMilliseconds` header value only needs to be used in cases where more granular timestamps are required.
## Reference Implementation
A reference implementation is not yet provided, and must be made available for this ACP to be considered `implementable`.
## Security Considerations
Too rapid block production may cause availability issues if validators of the given blockchain are not able to keep up with blocks being proposed to consensus. This new mechanism allows validators to help influence the maximum frequency at which blocks are allowed to be produced, but potential misconfiguration or overly aggressive settings may cause problems for some validators.
The mechanism for the minimum block delay time to adapt based on validator preference has already been used previously to allow for dynamic gas targets based on validator preference on the C-Chain, providing more confidence that it is suitable for controlling this network parameter as well. However, because each block is capable of changing the value of the minimum block delay by a certain amount, the lower the minimum block delay is, the more blocks that can be produced in a given time, and the faster the minimum block delay value will be able to change. This creates a dynamic where the mechanism for controlling `minimumBlockDelay` is more reactive at lower values, and less reactive at higher values. The global minimum `minimumBlockDelay` ($M$) provides a lower bound of how quickly blocks can ever be produced, but it is left to validators to ensure that the effective value does not exceed their collective preference.
## Acknowledgments
Thanks to [Luigi D'Onorio DeMeo](https://x.com/luigidemeo) for continually bringing up the idea of reducing block times to provide better UX for users of Avalanche blockchains.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-23: P Chain Native Transfers
URL: /docs/acps/23-p-chain-native-transfers
Details for Avalanche Community Proposal 23: P Chain Native Transfers
| ACP | 23 |
| :------------ | :--------------------------------------------------------- |
| **Title** | P-Chain Native Transfers |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
Support native transfers on P-chain. This enables users to transfer P-chain assets without leaving the P-chain or using a transaction type that's not meant for native transfers.
## Motivation
Currently, the P-chain has no simple transfer transaction type. The X-chain supports this functionality through a `BaseTx`. Although the P-chain contains transaction types that extend `BaseTx`, the `BaseTx` transaction type itself is not a valid transaction. This leads to abnormal implementations of P-chain native transfers like in the AvalancheGo wallet which abuses [`CreateSubnetTx`](https://github.com/ava-labs/avalanchego/blob/v1.10.15/wallet/chain/p/builder.go#L54-L63) to replicate the functionality contained in `BaseTx`.
With the growing number of subnets slated for launch on the Avalanche network, simple transfers will be demanded more by users. While there are work-arounds as mentioned before, the network should support it natively to provide a cheaper option for both validators and end-users.
## Specification
To support `BaseTx`, Avalanche Network Clients (like AvalancheGo) must register `BaseTx` with the type ID `0x22` in codec version `0x00`.
For the specification of the transaction itself, see [here](https://github.com/ava-labs/avalanchego/blob/v1.10.15/vms/platformvm/txs/base_tx.go#L29). Note that most other P-chain transactions extend this type, the only change in this ACP is to register it as a valid transaction itself.
## Backwards Compatibility
Adding a new transaction type is an execution change and requires a mandatory upgrade for activation. Implementors must take care to reject this transaction prior to activation. This ACP only details the specification of the added `BaseTx` transaction type.
## Reference Implementation
An implementation of `BaseTx` support was created [here](https://github.com/ava-labs/avalanchego/pull/2232) and subsequently merged into AvalancheGo. Since the "D" Upgrade is not activated, this transaction will be rejected by AvalancheGo.
If modifications are made to the specification of the transaction as part of the ACP process, the code must be updated prior to activation.
## Security Considerations
The P-chain has fixed fees which does not place any limits on chain throughput. A potentially popular transaction type like `BaseTx` may cause periods of high usage. The reference implementation in AvalancheGo sets the transaction fee to 0.001 AVAX as a deterrent (equivalent to `ImportTx` and `ExportTx`). This should be sufficient for the time being but a dynamic fee mechanism will need to be added to the P-chain in the future to mitigate this security concern. This is not addressed in this ACP as it requires a larger change to the fee dynamics on the P-chain as a whole.
## Open Questions
No open questions.
## Acknowledgements
Thanks to [@StephenButtolph](https://github.com/StephenButtolph) and [@abi87](https://github.com/abi87) for their feedback on the reference implementation.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-24: Shanghai Eips
URL: /docs/acps/24-shanghai-eips
Details for Avalanche Community Proposal 24: Shanghai Eips
| ACP | 24 |
| :------------ | :--------------------------------------------------------- |
| **Title** | Activate Shanghai EIPs on C-Chain |
| **Author(s)** | Darioush Jalali ([@darioush](https://github.com/darioush)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
This ACP proposes the adoption of the following EIPs on the Avalanche C-Chain network:
* [EIP-3651: Warm COINBASE](https://eips.ethereum.org/EIPS/eip-3651)
* [EIP-3855: PUSH0 instruction](https://eips.ethereum.org/EIPS/eip-3855)
* [EIP-3860: Limit and meter initcode](https://eips.ethereum.org/EIPS/eip-3860)
* [EIP-6049: Deprecate SELFDESTRUCT](https://eips.ethereum.org/EIPS/eip-6049)
## Motivation
The listed EIPs were activated on Ethereum mainnet as part of the [Shanghai upgrade](https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/shanghai.md#included-eips). This ACP proposes their activation on the Avalanche C-Chain in the next network upgrade. This maintains compatibility with upstream EVM tooling, infrastructure, and developer experience (e.g., Solidity compiler >= [0.8.20](https://github.com/ethereum/solidity/releases/tag/v0.8.20)).
## Specification & Reference Implementation
This ACP proposes the EIPs be adopted as specified in the EIPs themselves. ANCs (Avalanche Network Clients) can adopt the implementation as specified in the [coreth](https://github.com/ava-labs/coreth) repository, which was adopted from the [go-ethereum v1.12.0](https://github.com/ethereum/go-ethereum/releases/tag/v1.12.0) release in this [PR](https://github.com/ava-labs/coreth/pull/277). In particular, note the following code:
* [Activation of new opcode and dynamic gas calculations](https://github.com/ava-labs/coreth/blob/bf2051729c7aa0c4ed8848ad3a78e241a791b968/core/vm/jump_table.go#L92)
* [EIP-3860 intrinsic gas calculations](https://github.com/ava-labs/coreth/blob/bf2051729c7aa0c4ed8848ad3a78e241a791b968/core/state_transition.go#L112-L113)
* [EIP-3651 warm coinbase](https://github.com/ava-labs/coreth/blob/bf2051729c7aa0c4ed8848ad3a78e241a791b968/core/state/statedb.go#L1197-L1199)
* Note EIP-6049 marks SELFDESTRUCT as deprecated, but does not remove it. The implementation in coreth is unchanged.
## Backwards Compatibility
The following backward compatibility considerations were highlighted by the original EIP authors:
* [EIP-3855](https://eips.ethereum.org/EIPS/eip-3855#backwards-compatibility): "... introduces a new opcode which did not exist previously. Already deployed contracts using this opcode could change their behaviour after this EIP".
* [EIP-3860](https://eips.ethereum.org/EIPS/eip-3860#backwards-compatibility) "Already deployed contracts should not be effected, but certain transactions (with initcode beyond the proposed limit) would still be includable in a block, but result in an exceptional abort."
Adoption of this ACP modifies consensus rules for the C-Chain, therefore it requires a network upgrade.
## Security Considerations
Refer to the original EIPs for security considerations:
* [EIP 3855](https://eips.ethereum.org/EIPS/eip-3855#security-considerations)
* [EIP 3860](https://eips.ethereum.org/EIPS/eip-3860#security-considerations)
## Open Questions
No open questions.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-25: Vm Application Errors
URL: /docs/acps/25-vm-application-errors
Details for Avalanche Community Proposal 25: Vm Application Errors
| ACP | 25 |
| :------------ | :-------------------------------------------------------- |
| **Title** | Virtual Machine Application Errors |
| **Author(s)** | Joshua Kim ([@joshua-kim](https://github.com/joshua-kim)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
Support a way for a Virtual Machine (VM) to signal application-defined error conditions to another VM.
## Motivation
VMs are able to build their own peer-to-peer application protocols using the `AppRequest`, `AppResponse`, and `AppGossip` primitives.
`AppRequest` is a message type that requires a corresponding `AppResponse` to indicate a successful response. In the unhappy path where an `AppRequest` is unable to be served, there currently is no native way for a peer to signal an error condition. VMs currently resort to timeouts in failure cases, where a client making a request will fallback to marking its request as failed after some timeout period has expired.
Having a native application error type would offer a more powerful abstraction where Avalanche nodes would be able to score peers based on perceived errors. This is not currently possible because Avalanche networking isn't aware of the specific implementation details of the messages being delivered to VMs. A native application error type would also guarantee that all clients can potentially expect an `AppError` message to unblock an unsuccessful `AppRequest` and only rely on a timeout when absolutely necessary, significantly decreasing the latency for a client to unblock its request in the unhappy path.
## Specification
### Message
This modifies the p2p specification by introducing a new [protobuf](https://protobuf.dev/) message type:
```
message AppError {
bytes chain_id = 1;
uint32 request_id = 2;
uint32 error_code = 3;
string error_message = 4;
}
```
1. `chain_id`: Reserves field 1. Senders **must** use the same chain id of from the original `AppRequest` this `AppError` message is being sent in response to.
2. `request_id`: Reserves field 2. Senders **must** use the same request id from the original `AppRequest` this `AppError` message is being sent in response to.
3. `error_code`: Reserves field 3. Application defined error code. Implementations *should* use the same error codes for the same conditions to allow clients to error match. Negative error codes are reserved for protocol defined errors. VMs may reserve any error code greater than zero.
4. `error_message`: Reserves field 4. Application defined human-readable error message that *should not* be used for error matching. For error matching, use `error_code`.
### Reserved Errors
The following error codes are currently reserved by the Avalanche protocol:
| Error Code | Description |
| ---------- | --------------- |
| 0 | undefined |
| -1 | network timeout |
### Handling
Clients **must** respond to an inbound `AppRequest` message with either a corresponding `AppResponse` to indicate a successful response, or an `AppError` to indicate an error condition by the requested `deadline` in the original `AppRequest`.
## Backwards Compatibility
This new message type requires a network activation to require either an `AppResponse` or an `AppError` as a required response to an `AppRequest`.
## Reference Implementation
* Message definition: [https://github.com/ava-labs/avalanchego/pull/2111](https://github.com/ava-labs/avalanchego/pull/2111)
* Handling: [https://github.com/ava-labs/avalanchego/pull/2248](https://github.com/ava-labs/avalanchego/pull/2248)
## Security Considerations
Optional section that discusses the security implications/considerations relevant to the proposed change.
Clients should be aware that peers can arbitrarily send `AppError` messages to invoke error handling logic in a VM.
## Open Questions
Optional section that lists any concerns that should be resolved prior to implementation.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-30: Avalanche Warp X Evm
URL: /docs/acps/30-avalanche-warp-x-evm
Details for Avalanche Community Proposal 30: Avalanche Warp X Evm
| ACP | 30 |
| :------------ | :------------------------------------------------------------------------------- |
| **Title** | Integrate Avalanche Warp Messaging into the EVM |
| **Author(s)** | Aaron Buchwald ([aaron.buchwald56@gmail.com](mailto:aaron.buchwald56@gmail.com)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
Integrate Avalanche Warp Messaging into the C-Chain and Subnet-EVM in order to bring Cross-Subnet Communication to the EVM on Avalanche.
## Motivation
Avalanche Subnets enable the creation of independent blockchains within the Avalanche Network. Each Avalanche Subnet registers its validator set on the Avalanche P-Chain, which serves as an effective "membership chain" for the entire Avalanche Ecosystem.
By providing read access to the validator set of every Subnet on the Avalanche Network, any Subnet can look up the validator set of any other Subnet within the Avalanche Ecosystem to verify an Avalanche Warp Message, which replaces the need for point-to-point exchange of validator set info between Subnets. This enables a light weight protocol that allows seamless, on-demand communication between Subnets.
For more information on the Avalanche Warp Messaging message and payload formats see here:
* [AWM Message Format](https://github.com/ava-labs/avalanchego/tree/v1.10.15/vms/platformvm/warp/README.md)
* [Payload Format](https://github.com/ava-labs/avalanchego/tree/v1.10.15/vms/platformvm/warp/payload/README.md)
This ACP proposes to activate Avalanche Warp Messaging on the C-Chain and offer compatible support in Subnet-EVM to provide the first standard implementation of AWM in production on the Avalanche Network.
## Specification
The specification will be broken down into the Solidity interface of the Warp Precompile, a Golang example implementation, the predicate verification, and the proposed gas costs for the Warp Precompile.
The Warp Precompile address is `0x0200000000000000000000000000000000000005`.
### Precompile Solidity Interface
```solidity
// (c) 2022-2023, Ava Labs, Inc. All rights reserved.
// See the file LICENSE for licensing terms.
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
struct WarpMessage {
bytes32 sourceChainID;
address originSenderAddress;
bytes payload;
}
struct WarpBlockHash {
bytes32 sourceChainID;
bytes32 blockHash;
}
interface IWarpMessenger {
event SendWarpMessage(address indexed sender, bytes32 indexed messageID, bytes message);
// sendWarpMessage emits a request for the subnet to send a warp message from [msg.sender]
// with the specified parameters.
// This emits a SendWarpMessage log from the precompile. When the corresponding block is accepted
// the Accept hook of the Warp precompile is invoked with all accepted logs emitted by the Warp
// precompile.
// Each validator then adds the UnsignedWarpMessage encoded in the log to the set of messages
// it is willing to sign for an off-chain relayer to aggregate Warp signatures.
function sendWarpMessage(bytes calldata payload) external returns (bytes32 messageID);
// getVerifiedWarpMessage parses the pre-verified warp message in the
// predicate storage slots as a WarpMessage and returns it to the caller.
// If the message exists and passes verification, returns the verified message
// and true.
// Otherwise, returns false and the empty value for the message.
function getVerifiedWarpMessage(uint32 index) external view returns (WarpMessage calldata message, bool valid);
// getVerifiedWarpBlockHash parses the pre-verified WarpBlockHash message in the
// predicate storage slots as a WarpBlockHash message and returns it to the caller.
// If the message exists and passes verification, returns the verified message
// and true.
// Otherwise, returns false and the empty value for the message.
function getVerifiedWarpBlockHash(
uint32 index
) external view returns (WarpBlockHash calldata warpBlockHash, bool valid);
// getBlockchainID returns the snow.Context BlockchainID of this chain.
// This blockchainID is the hash of the transaction that created this blockchain on the P-Chain
// and is not related to the Ethereum ChainID.
function getBlockchainID() external view returns (bytes32 blockchainID);
}
```
### Warp Predicates and Pre-Verification
Signed Avalanche Warp Messages are encoded in the [EIP-2930 Access List](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2930.md) of a transaction, so that they can be pre-verified before executing the transactions in the block.
The access list can specify any number of access tuples: a pair of an address and an array of storage slots in EIP-2930. Warp Predicate verification borrows this functionality to encode signed warp messages according to the serialization format defined [here](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/predicate/Predicate.md).
Each Warp specific access tuple included in the access list specifies the Warp Precompile address as the address. The first tuple that specifies the Warp Precompile address is considered to be at index. Each subsequent access tuple that specifies the Warp Precompile address increases the Warp Message index by 1. Access tuples that specify any other address are not included in calculating the index for a specific warp message.
Avalanche Warp Messages are pre-verified (prior to block execution), and outputs a bitset for each transaction where a 1 indicates an Avalanche Warp Message that failed verification at that index. Throughout the EVM execution, the Warp Precompile checks the status of the resulting bit set to determine whether pre-verified messages are considered valid. This has the additional benefit of encoding the Warp pre-verification results in the block, so that verifying a historical block can use the encoded results instead of needing to access potentially old P-Chain state. The result bitset is encoded in the block according to the predicate result specification [here](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/predicate/Results.md).
Each Warp Message in the access list is charged gas to pay for verifying the Warp Message (gas costs are covered below) and is verified with the following steps (see [here](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/x/warp/config.go#L218) for reference implementation):
1. Unpack the predicate bytes
2. Parse the signed Avalanche Warp Message
3. Verify the signature according to the AWM spec in AvalancheGo [here](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/x/warp/config.go#L218) (the quorum numerator/denominator for the C-Chain is 67/100 and is configurable in Subnet-EVM)
### Precompile Implementation
All types, events, and function arguments/outputs are encoded using the ABI package according to the official [Solidity ABI Specification](https://docs.soliditylang.org/en/latest/abi-spec.html).
When the precompile is invoked with a given `calldata` argument, the first four bytes (`calldata[0:4]`) are read as the [function selector](https://docs.soliditylang.org/en/latest/abi-spec.html#function-selector). If the function selector matches the function selector of one of the functions defined by the Solidity interface, the contract invokes the corresponding execution function with the remaining calldata ie. `calldata[4:]`.
For the full specification of the execution functions defined in the Solidity interface, see the reference implementation here:
* [sendWarpMessage](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/x/warp/contract.go#L226)
* [getVerifiedWarpMessage](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/x/warp/contract.go#L187)
* [getVerifiedWarpBlockHash](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/x/warp/contract.go#L145)
* [getBlockchainID](https://github.com/ava-labs/subnet-evm/blob/v0.5.9/x/warp/contract.go#L96)
### Gas Costs
The Warp Precompile charges gas during the verification of included Avalanche Warp Messages, which is included in the intrinsic gas cost of the transaction, and during the execution of the precompile.
#### Verification Gas Costs
Pre-verification charges the following costs for each Avalanche Warp Message:
* GasCostPerSignatureVerification: 20000
* GasCostPerWarpMessageBytes: 100
* GasCostPerWarpSigner: 500
These numbers were determined experimentally using the benchmarks available [here](https://github.com/ava-labs/subnet-evm/blob/master/x/warp/predicate_test.go#L687) to target approximately the same mgas/s as existing precompile benchmarks in the EVM, which ranges between 50-200 mgas/s.
In addition to the benchmarks, the following assumptions and goals were taken into account:
* BLS Public Key Aggregation is extremely fast, resulting in charging more for the base cost of a single BLS Multi-Signature Verification than for adding an additional public key
* The cost per byte included in the transaction should be strictly higher for including Avalanche Warp Messages than via transaction calldata, so that the Warp Precompile does not change the worst case maximum block size
#### Execution Gas Costs
The execution gas costs were determined by summing the cost of the EVM operations that are performed throughout the execution of the precompile with special consideration for added functionality that does not have an existing corollary within the EVM.
##### sendWarpMessage
`sendWarpMessage` charges a base cost of 41,500 gas + 8 gas / payload byte
This is comprised of charging for the following components:
* 375 gas / log operation
* 3 topics \* 375 gas / topic
* 20k gas to produce and serve a BLS Signature
* 20k gas to store the Unsigned Warp Message
* 8 gas / payload byte
This charges 20k gas for storing an Unsigned Warp Message although the message is stored in an independent key-value database instead of the active state. This makes it less expensive to store, so 20k gas is a conservative estimate.
Additionally, the cost of serving valid signatures is significantly cheaper than serving state sync and bootstrapping requests, so the cost to validators of serving signatures over time is not considered a significant concern.
`sendWarpMessage` also charges for the log operation it includes commensurate with the gas cost of a standard log operation in the EVM.
A single `SendWarpMessage` log is charged:
* 375 gas base cost
* 375 gas per topic (`eventID`, `sender`, `messageID`)
* 8 byte per / payload byte encoded in the `message` field
Topics are indexed fields encoded as 32 byte values to support querying based on given specified topic values.
##### getBlockchainID
`getBlockchainID` charges 2 gas to serve an already in-memory 32 byte valu commensurate with existing in-memory operations.
##### getVerifiedWarpBlockHash / getVerifiedWarpMessage
`GetVerifiedWarpMessageBaseCost` charges 2 gas for serving a Warp Message (either payload type). Warp message are already in-memory, so it charges 2 gas for access.
`GasCostPerWarpMessageBytes` charges 100 gas per byte of the Avalanche Warp Message that is unpacked into a Solidity struct.
## Backwards Compatibility
Existing EVM opcodes and precompiles are not modified by activating Avalanche Warp Messaging in the EVM. This is an additive change to activate a Warp Precompile on the Avalanche C-Chain and can be scheduled for activation in any VM running on Avalanche Subnets that are capable of sending / verifying the specified payload types.
## Reference Implementation
A full reference implementation can be found in Subnet-EVM v0.5.9 [here](https://github.com/ava-labs/subnet-evm/tree/v0.5.9/x/warp).
## Security Considerations
Verifying an Avalanche Warp Message requires reading the source subnet's validator set at the P-Chain height specified in the [Snowman++ Block Extension](https://github.com/ava-labs/avalanchego/blob/v1.10.15/vms/proposervm/README.md#snowman-block-extension). The Avalanche PlatformVM provides the current state of the Avalanche P-Chain and maintains reverse diff-layers in order to compute Subnets' validator sets at historical points in time.
As a result, verifying a historical Avalanche Warp Message that references an old P-Chain height requires applying diff-layers from the current state back to the referenced P-Chain height. As Subnets and the P-Chain continue to produce and accept new blocks, verifying the Warp Messages in historical blocks becomes increasingly expensive.
To efficiently handle historical blocks containing Avalanche Warp Messages, the EVM uses the result bitset encoded in the block to determine the validity of Avalanche Warp Messages without requiring a historical P-Chain state lookup. This is considered secure because the network already verified the Avalanche Warp Messages when they were originally verified and accepted.
## Open Questions
*How should validator set lookups in Warp Message verification be effectively charged for gas?*
The verification cost of performing a validator set lookup on the P-Chain is currently excluded from the implementation. The cost of this lookup is variable depending on how old the referenced P-Chain height is from the perspective of each validator.
[Ongoing work](https://github.com/ava-labs/avalanchego/pull/1611) can parallelize P-Chain validator set lookups and message verification to reduce the impact on block verification latency to be negligible and reduce costs to reflect the additional bandwidth of encoding Avalanche Warp Messages in the transaction.
## Acknowledgements
Avalanche Warp Messaging and this effort to integrate it into the EVM has been a monumental effort. Thanks to all of the contributors who contributed their ideas, feedback, and development to this effort.
@stephenbuttolph
@patrick-ogrady
@michaelkaplan13
@minghinmatthewlam
@cam-schultz
@xanderdunn
@darioush
@ceyonur
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-31: Enable Subnet Ownership Transfer
URL: /docs/acps/31-enable-subnet-ownership-transfer
Details for Avalanche Community Proposal 31: Enable Subnet Ownership Transfer
| ACP | 31 |
| :------------ | :--------------------------------------------------------- |
| **Title** | Enable Subnet Ownership Transfer |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
Allow the current owner of a Subnet to transfer ownership to a new owner.
## Motivation
Once a Subnet is created on the P-chain through a [CreateSubnetTx](https://github.com/ava-labs/avalanchego/blob/v1.10.15/vms/platformvm/txs/create_subnet_tx.go#L14-L19), the `Owner` of the subnet is currently immutable. Subnet operators may want to transition ownership of the Subnet to a new owner for a number of reasons, not least of all being rotating their control key(s) periodically.
## Specification
Implement a new transaction type (`TransferSubnetOwnershipTx`) that:
1. Takes in a `Subnet`
2. Verifies that the `SubnetAuth` has the right to remove the node from the subnet by verifying it against the `Owner` field in the `CreateSubnetTx` that created the `Subnet`.
3. Takes in a new `Owner` and assigning it as the new owner of `Subnet`
This transaction type should have the following format (code below is presented in Golang):
```go
type TransferSubnetOwnershipTx struct {
// Metadata, inputs and outputs
BaseTx `serialize:"true"`
// ID of the subnet this tx is modifying
Subnet ids.ID `serialize:"true" json:"subnetID"`
// Proves that the issuer has the right to remove the node from the subnet.
SubnetAuth verify.Verifiable `serialize:"true" json:"subnetAuthorization"`
// Who is now authorized to manage this subnet
Owner fx.Owner `serialize:"true" json:"newOwner"`
}
```
This transaction type should have type ID `0x21` in codec version `0x00`.
This transaction type should have a fee of `0.001 AVAX`, equivalent to adding a subnet validator/delegator.
## Backwards Compatibility
Adding a new transaction type is an execution change and requires a mandatory upgrade for activation. Implementors must take care to reject this transaction prior to activation. This ACP only details the specification of the `TransferSubnetOwnershipTx` type.
## Reference Implementation
An implementation of `TransferSubnetOwnershipTx` was created [here](https://github.com/ava-labs/avalanchego/pull/2178) and subsequently merged into AvalancheGo. Since the "D" Upgrade is not activated, this transaction will be rejected by AvalancheGo.
If modifications are made to the specification of the transaction as part of the ACP process, the code must be updated prior to activation.
## Security Considerations
No security considerations.
## Open Questions
No open questions.
## Acknowledgements
Thank you [@friskyfoxdk](https://github.com/friskyfoxdk) for filing an [issue](https://github.com/ava-labs/avalanchego/issues/1946) requesting this feature. Thanks to [@StephenButtolph](https://github.com/StephenButtolph) and [@abi87](https://github.com/abi87) for their feedback on the reference implementation.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-41: Remove Pending Stakers
URL: /docs/acps/41-remove-pending-stakers
Details for Avalanche Community Proposal 41: Remove Pending Stakers
| ACP | 41 |
| :------------ | :--------------------------------------------------------- |
| **Title** | Remove Pending Stakers |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
Remove user-specified `StartTime` for stakers. Start the staking period for a staker as soon as their staking transaction is accepted. This greatly reduces the computational load on the P-chain, increasing the efficiency of all Avalanche Network validators.
## Motivation
Stakers currently set a `StartTime` for their staking period. This means that Avalanche Network Clients, like AvalancheGo, need to maintain a pending set of all stakers that have not yet started. This places a nontrivial amount of work on the P-chain:
* When a new delegator transaction is verified, the pending set needs to be checked to ensure that the validator they are delegating to will not exceed `MaxValidatorStake` while they are active
* When a new staker transaction is accepted, it gets added to the pending set
* When time is advanced on the P-chain, any stakers in the pending set whose `StartTime <= CurrentTime` need to be moved to the current set
By immediately starting every staker on acceptance, the validators do not have to do the above work when validating the P-chain. `MaxValidatorStake` will become an `O(1)` operation as only the current stake of the validator needs to be checked. The pending set can be fully removed.
## Specification
1. When adding a new staker, the current on-chain time should be used for the staker's start time.
2. When determining when to remove the staker from the staker set, the `EndTime` specified in the transaction should continue to be used. Staking transactions should now be rejected if it does not satisfy `MinStakeDuration <= EndTime - CurrentTime <= MaxStakeDuration`. `StartTime` will no longer be validated.
## Backwards Compatibility
Modifying the state transition of a transaction type is an execution change and requires a mandatory upgrade for activation. Implementors must take care to not alter the execution behavior prior to activation. This ACP only details the new state transition.
Current wallet implementations will continue to work as-is post-activation of this ACP since no transaction formats are modified or added. Wallet implementations may run into issues with their txs being rejected as a result of this ACP if `EndTime >= CurrentChainTime + MaxStakeDuration`. `CurrentChainTime` is guaranteed to be >= the latest block timestamp on the P-chain.
## Reference Implementation
A reference implementation has not been created for this ACP since it deals with state management. Each ANC will need to adjust their execution step to follow the Specification detailed above. For AvalancheGo, this work is tracked in this PR: [https://github.com/ava-labs/avalanchego/pull/2175](https://github.com/ava-labs/avalanchego/pull/2175)
If modifications are made to the specification of the new execution behavior as part of the ACP process, the code must be updated prior to activation.
## Security Considerations
No security considerations.
## Open Questions
*How will stakers stake for `MaxStakeDuration` if they cannot determine their `StartTime`?*
As mentioned above, the beginning of your staking period is the block acceptance timestamp. Unless you can accurately predict the block timestamp, you will *not* be able to fully stake for `MaxStakeDuration`. This is an explicit trade-off to guarantee that stakers will receive their original stake + any staking rewards at `EndTime`.
Delegators can maximize their staking period by setting the same `EndTime` as the Validator they are delegating to.
## Acknowledgements
Thanks to [@StephenButtolph](https://github.com/StephenButtolph) and [@abi87](https://github.com/abi87) for their feedback on these ideas.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-62: Disable Addvalidatortx And Adddelegatortx
URL: /docs/acps/62-disable-addvalidatortx-and-adddelegatortx
Details for Avalanche Community Proposal 62: Disable Addvalidatortx And Adddelegatortx
| ACP | 62 |
| :------------ | :------------------------------------------------------------------------------------------------------------------------- |
| **Title** | Disable `AddValidatorTx` and `AddDelegatorTx` |
| **Author(s)** | Jacob Everly ([@JacobEv3rly](https://twitter.com/JacobEv3rly)), Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated |
| **Track** | Standards |
## Abstract
Disable `AddValidatorTx` and `AddDelegatorTx` to push all new stakers to use `AddPermissionlessValidatorTx` and `AddPermissionlessDelegatorTx`. `AddPermissionlessValidatorTx` requires validators to register a BLS key. Wide adoption of registered BLS keys accelerates the timeline for future P-Chain upgrades. Additionally, this reduces the number of ways to participate in Primary Network validation from two to one.
## Motivation
`AddPermissionlessValidatorTx` and `AddPermissionlessDelegatorTx` were activated on the Avalanche Network in October 2022 with Banff (v1.9.0). This unlocked the ability for Subnet creators to activate Proof-of-Stake validation using their own token on their own Subnet. See more details about Banff [here](https://medium.com/avalancheavax/banff-elastic-subnets-44042f41e34c).
These new transaction types can also be used to register a Primary Network validator, leaving two redundant transactions: `AddValidatorTx` and `AddDelegatorTx`.
[`AddPermissionlessDelegatorTx`](https://github.com/ava-labs/avalanchego/blob/v1.10.18/vms/platformvm/txs/add_permissionless_delegator_tx.go#L25-L37) contains the same fields as [`AddDelegatorTx`](https://github.com/ava-labs/avalanchego/blob/v1.10.18/vms/platformvm/txs/add_delegator_tx.go#L29-L39) with an additional `Subnet` field.
[`AddPermissionlessValidatorTx`](https://github.com/ava-labs/avalanchego/blob/v1.10.18/vms/platformvm/txs/add_permissionless_validator_tx.go#L35-L59) contains the same fields as [`AddValidatorTx`](https://github.com/ava-labs/avalanchego/blob/v1.10.18/vms/platformvm/txs/add_validator_tx.go#L29-L42) with additional `Subnet` and `Signer` fields. `RewardsOwner` was also split into `ValidationRewardsOwner` and `DelegationRewardsOwner` letting validators divert rewards they receive from delegators into a separate rewards owner.
By disabling support of `AddValidatorTx`, all new validators on the Primary Network must use `AddPermissionlessValidatorTx` and register a BLS key with their NodeID. As more validators attach BLS keys to their nodes, future upgrades using these BLS keys can be activated through the ACP process. BLS keys can be used to efficiently sign a common message via [Public Key Aggregation](https://crypto.stanford.edu/~dabo/pubs/papers/BLSmultisig.html). Applications of this include, but are not limited to:
* **Arbitrary Subnet Rewards**: The P-Chain currently restricts Elastic Subnets to follow the reward curve defined in a `TransformSubnetTx`. With sufficient BLS key adoption, Elastic Subnets can define their own reward curve and reward conditions. The P-Chain can be modified to take in a message indicating if a Subnet validator should be rewarded with how many tokens signed with a BLS Multi-Signature.
* **Subnet Attestations**: Elastic Subnets can attest to the state of their Subnet with a BLS Multi-Signature. This can enable clients to fetch the current state of the Subnet without syncing the entire Subnet. `StateSync` enables clients to download chain state from peers up to a recent block near tip. However, it is up to the client to query these peers and resolve any potential conflicts in the responses. With Subnet Attestations, clients can query an API node to prove information about a Subnet without querying the Subnet's validators. This can especially be useful for [Subnet-Only Validators](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/62-disable-addvalidatortx-and-adddelegatortx/13-subnet-only-validators.md) to prove information about the C-Chain.
To accelerate future BLS-powered advancements in the Avalanche Network, this ACP aims to disable `AddValidatorTx` and `AddDelegatorTx` in Durango.
## Specification
`AddValidatorTx` and `AddDelegatorTx` should be marked as dropped when added to the mempool after activation. Any blocks including these transactions should be considered invalid.
## Backwards Compatibility
Disabling a transaction type is an execution change and requires a mandatory upgrade for activation. Implementers must take care to not alter the execution behavior prior to activation.
After this ACP is activated, any new issuance of `AddValidatorTx` or `AddDelegatorTx` will be considered invalid and dropped by the network. Any consumers of these transactions must transition to using `AddPermissionlessValidatorTx` and `AddPermissionlessDelegatorTx` to participate in Primary Network validation. The [Avalanche Ledger App](https://github.com/LedgerHQ/app-avalanche) supports both of these transaction types.
Note that `AddSubnetValidatorTx` and `RemoveSubnetValidatorTx` are unchanged by this ACP.
## Reference Implementation
An implementation disabling `AddValidatorTx` and `AddDelegatorTx` was created [here](https://github.com/ava-labs/avalanchego/pull/2662). Until activation, these transactions will continue to be accepted by AvalancheGo.
If modifications are made to the specification as part of the ACP process, the code must be updated prior to activation.
## Security Considerations
No security considerations.
## Open Questions
## Acknowledgements
Thanks to [@StephenButtolph](https://github.com/StephenButtolph) and [@patrick-ogrady](https://github.com/patrick-ogrady) for their feedback on these ideas.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-75: Acceptance Proofs
URL: /docs/acps/75-acceptance-proofs
Details for Avalanche Community Proposal 75: Acceptance Proofs
| ACP | 75 |
| :------------ | :----------------------------------------------------------------------------------- |
| **Title** | Acceptance Proofs |
| **Author(s)** | Joshua Kim |
| **Status** | Proposed ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/82)) |
| **Track** | Standards |
## Abstract
Introduces support for a proof of a block’s acceptance in consensus.
## Motivation
Subnets are able to prove arbitrary events using warp messaging, but native support for proving block acceptance at the protocol layer enables more utility. Acceptance proofs are introduced to prove that a block has been accepted by a subnet. One example use case for acceptance proofs is to provide stronger fault isolation guarantees from the primary network to subnets.
Subnets use the [ProposerVM](https://github.com/ava-labs/avalanchego/blob/416fbdf1f783c40f21e7009a9f06d192e69ba9b5/vms/proposervm/README.md) to implement soft leader election for block proposal. The ProposerVM determines the block producer schedule from a randomly shuffled validator set at a specified P-Chain block height. Validators are therefore required to have the P-Chain block referenced in a block's header to verify the block producer against the expected block producer schedule. If a block's header specifies a P-Chain height that has not been accepted yet, the block is treated as invalid. If a block referencing an unknown P-Chain height was produced virtuously, it is expected that the validator will eventually discover the block as its P-Chain height advances and accept the block.
If many validators disagree about the current tip of the P-Chain, it can lead to a liveness concern on the subnet where block production entirely stalls. In practice, this almost never occurs because nodes produce blocks with a lagging P-Chain height because it’s likely that most nodes will have accepted a sufficiently stale block. This however, relies on an assumption that validators are constantly making progress in consensus on the P-Chain to prevent the subnet from stalling. This leaves an open concern where the P-Chain stalling on a node would prevent it from verifying any blocks, leading to a subnet unable to produce blocks if many validators stalled at different P-Chain heights.
***
Figure 1: A Validator that has synced P-Chain blocks `A` and `B` fails verification of a block proposed at block `C`.
 ***
We introduce "acceptance proofs", so that a peer can verify any block accepted by consensus. In the aforementioned use-case, if a P-Chain block is unknown by a peer, it can request the block and proof at the provided height from a peer. If a block's proof is valid, the block can be executed to advance the local P-Chain and verify the proposed subnet block. Peers can request blocks from any peer without requiring consensus locally or communication with a validator. This has the added benefit of reducing the number of required connections and p2p message load served by P-Chain validators.
***
Figure 2: A Validator is verifying a subnet’s block `Z` which references an unknown P-Chain block `C` in its block header
***
We introduce "acceptance proofs", so that a peer can verify any block accepted by consensus. In the aforementioned use-case, if a P-Chain block is unknown by a peer, it can request the block and proof at the provided height from a peer. If a block's proof is valid, the block can be executed to advance the local P-Chain and verify the proposed subnet block. Peers can request blocks from any peer without requiring consensus locally or communication with a validator. This has the added benefit of reducing the number of required connections and p2p message load served by P-Chain validators.
***
Figure 2: A Validator is verifying a subnet’s block `Z` which references an unknown P-Chain block `C` in its block header
 Figure 3: A Validator requests the blocks and proofs for `B` and `C` from a peer
Figure 3: A Validator requests the blocks and proofs for `B` and `C` from a peer
 Figure 4: The Validator accepts the P-Chain blocks and is now able to verify `Z`
Figure 4: The Validator accepts the P-Chain blocks and is now able to verify `Z`
 ***
## Specification
Note: The following is pseudocode.
### P2P
#### Aggregation
```diff
+ message GetAcceptanceSignatureRequest {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes block_id = 3;
+ }
```
The `GetAcceptanceSignatureRequest` message is sent to a peer to request their signature for a given block id.
```diff
+ message GetAcceptanceSignatureResponse {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes bls_signature = 3;
+ }
```
`GetAcceptanceSignatureResponse` is sent to a peer as a response for `GetAcceptanceSignatureRequest`. `bls_signature` is the peer’s signature using their registered primary network BLS staking key over the requested `block_id`. An empty `bls_signature` field indicates that the block was not accepted yet.
## Security Considerations
Nodes that bootstrap using state sync may not have the entire history of the
P-Chain and therefore will not be able to provide the entire history for a block
that is referenced in a block that they propose. This would be needed to unblock a node that is attempting to fast-forward their P-Chain, as they require the entire ancestry between their current accepted tip and the block they are attempting to forward to. It is assumed that nodes will have some minimum amount of recent state so that the requester can eventually be unblocked by retrying, as only one node with the requested ancestry is required to unblock the requester.
An alternative is to make a churn assumption and validate the proposed block's proof with a stale validator set to avoid complexity, but this introduces more security concerns.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-77: Reinventing Subnets
URL: /docs/acps/77-reinventing-subnets
Details for Avalanche Community Proposal 77: Reinventing Subnets
| ACP | 77 |
| :------------ | :-------------------------------------------------------------------------------------------------------- |
| **Title** | Reinventing Subnets |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/78)) |
| **Track** | Standards |
| **Replaces** | [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) |
## Abstract
Overhaul Subnet creation and management to unlock increased flexibility for Subnet creators by:
* Separating Subnet validators from Primary Network validators (Primary Network Partial Sync, Removal of 2000 \$AVAX requirement)
* Moving ownership of Subnet validator set management from P-Chain to Subnets (ERC-20/ERC-721/Arbitrary Staking, Staking Reward Management)
* Introducing a continuous P-Chain fee mechanism for Subnet validators (Continuous Subnet Staking)
This ACP supersedes [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) and borrows some of its language.
## Motivation
Each node operator must stake at least 2000 $AVAX ($70k at time of writing) to first become a Primary Network validator before they qualify to become a Subnet validator. Most Subnets aim to launch with at least 8 Subnet validators, which requires staking 16000 $AVAX ($560k at time of writing). All Subnet validators, to satisfy their role as Primary Network validators, must also [allocate 8 AWS vCPU, 16 GB RAM, and 1 TB storage](https://github.com/ava-labs/avalanchego/blob/master/README.md#installation) to sync the entire Primary Network (X-Chain, P-Chain, and C-Chain) and participate in its consensus, in addition to whatever resources are required for each Subnet they are validating.
Regulated entities that are prohibited from validating permissionless, smart contract-enabled blockchains (like the C-Chain) cannot launch a Subnet because they cannot opt-out of Primary Network Validation. This deployment blocker prevents a large cohort of Real World Asset (RWA) issuers from bringing unique, valuable tokens to the Avalanche Ecosystem (that could move between C-Chain \<-> Subnets using Avalanche Warp Messaging/Teleporter).
A widely validated Subnet that is not properly metered could destabilize the Primary Network if usage spikes unexpectedly. Underprovisioned Primary Network validators running such a Subnet may exit with an OOM exception, see degraded disk performance, or find it difficult to allocate CPU time to P/X/C-Chain validation. The inverse also holds for Subnets with the Primary Network (where some undefined behavior could bring a Subnet offline).
Although the fee paid to the Primary Network to operate a Subnet does not go up with the amount of activity on the Subnet, the fixed, upfront cost of setting up a Subnet validator on the Primary Network deters new projects that prefer smaller, even variable, costs until demand is observed. *Unlike L2s that pay some increasing fee (usually denominated in units per transaction byte) to an external chain for data availability and security as activity scales, Subnets provide their own security/data availability and the only cost operators must pay from processing more activity is the hardware cost of supporting additional load.*
Elastic Subnets, introduced in [Banff](https://medium.com/avalancheavax/banff-elastic-subnets-44042f41e34c), enabled Subnet creators to activate Proof-of-Stake validation and uptime-based rewards using their own token. However, this token is required to be an ANT (created on the X-Chain) and locked on the P-Chain. All staking rewards were distributed on the P-Chain with the reward curve being defined in the `TransformSubnetTx` and, once set, was unable to be modified.
With no Elastic Subnets live on Mainnet, it is clear that Permissionless Subnets as they stand today could be more desirable. There are many successful Permissioned Subnets in production but many Subnet creators have raised the above as points of concern. In summary, the Avalanche community could benefit from a more flexible and affordable mechanism to launch Permissionless Subnets.
### A Note on Nomenclature
Avalanche Subnets are subnetworks validated by a subset of the Primary Network validator set. The new network creation flow outlined in this ACP does not require any intersection between the new network's validator set and the Primary Network's validator set. Moreover, the new networks have greater functionality and sovereignty than Subnets. To distinguish between these two kinds of networks, the community has been referring to these new networks as *Avalanche Layer 1s*, or L1s for short.
All networks created through the old network creation flow will continue to be referred to as Avalanche Subnets.
## Specification
At a high-level, L1s can manage their validator sets externally to the P-Chain by setting the blockchain ID and address of their *validator manager*. The P-Chain will consume Warp messages that modify the L1's validator set. To confirm modification of the L1's validator set, the P-Chain will also produce Warp messages. L1 validators are not required to validate the Primary Network, and do not have the same 2000 $AVAX stake requirement that Subnet validators have. To maintain an active L1 validator, a continuous fee denominated in $AVAX is assessed. L1 validators are only required to sync the P-Chain (not X/C-Chain) in order to track validator set changes and support cross-L1 communication.
### P-Chain Warp Message Payloads
To enable management of an L1's validator set externally to the P-Chain, Warp message verification will be added to the [`PlatformVM`](https://github.com/ava-labs/avalanchego/tree/master/vms/platformvm). For a Warp message to be considered valid by the P-Chain, at least 67% of the `sourceChainID`'s weight must have participated in the aggregate BLS signature. This is equivalent to the threshold set for the C-Chain. A future ACP may be proposed to support modification of this threshold on a per-L1 basis.
The following Warp message payloads are introduced on the P-Chain:
* `SubnetToL1ConversionMessage`
* `RegisterL1ValidatorMessage`
* `L1ValidatorRegistrationMessage`
* `L1ValidatorWeightMessage`
The method of requesting signatures for these messages is left unspecified. A viable option for supporting this functionality is laid out in [ACP-118](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/118-warp-signature-request/README.md) with the `SignatureRequest` message.
All node IDs contained within the message specifications are represented as variable length arrays such that they can support new node IDs types should the P-Chain add support for them in the future.
The serialization of each of these messages is as follows.
#### `SubnetToL1ConversionMessage`
The P-Chain can produce a `SubnetToL1ConversionMessage` for consumers (i.e. validator managers) to be aware of the initial validator set.
The following serialization is defined as the `ValidatorData`:
| Field | Type | Size |
| -------------: | ---------: | -----------------------: |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 60 + len(`nodeID`) bytes |
The following serialization is defined as the `ConversionData`:
| Field | Type | Size |
| ---------------: | ----------------: | ---------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `managerChainID` | `[32]byte` | 32 bytes |
| `managerAddress` | `[]byte` | 4 + len(`managerAddress`) bytes |
| `validators` | `[]ValidatorData` | 4 + sum(`validatorLengths`) bytes |
| | | 74 + len(`managerAddress`) + sum(`validatorLengths`) bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `sum(validatorLengths)` is the sum of the lengths of `ValidatorData` serializations included in `validators`.
* `subnetID` identifies the Subnet that is being converted to an L1 (described further below).
* `managerChainID` and `managerAddress` identify the validator manager for the newly created L1. This is the (blockchain ID, address) tuple allowed to send Warp messages to modify the L1's validator set.
* `validators` are the initial continuous-fee-paying validators for the given L1.
The `SubnetToL1ConversionMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `conversionID` | `[32]byte` | 32 bytes |
| | | 38 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000000` for this message
* `conversionID` is the SHA256 hash of the `ConversionData` from a given `ConvertSubnetToL1Tx`
#### `RegisterL1ValidatorMessage`
The P-Chain can consume a `RegisterL1ValidatorMessage` from validator managers through a `RegisterL1ValidatorTx` to register an addition to the L1's validator set.
The following is the serialization of a `PChainOwner`:
| Field | Type | Size |
| ----------: | -----------: | ---------------------------------: |
| `threshold` | `uint32` | 4 bytes |
| `addresses` | `[][20]byte` | 4 + len(`addresses`) \\\* 20 bytes |
| | | 8 + len(`addresses`) \\\* 20 bytes |
* `threshold` is the number of `addresses` that must provide a signature for the `PChainOwner` to authorize an action.
* Validation criteria:
* If `threshold` is `0`, `addresses` must be empty
* `threshold` \<= len(`addresses`)
* Entries of `addresses` must be unique and sorted in ascending order
The `RegisterL1ValidatorMessage` is specified as an `AddressedCall` with a payload of:
| Field | Type | Size |
| ----------------------: | ------------: | --------------------------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `expiry` | `uint64` | 8 bytes |
| `remainingBalanceOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `disableOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 122 + len(`nodeID`) + (len(`addresses1`) + len(`addresses2`)) \\\* 20 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000001` for this payload
* `subnetID`, `nodeID`, `weight`, and `blsPublicKey` are for the validator being added
* `expiry` is the time at which this message becomes invalid. As of a P-Chain timestamp `>= expiry`, this Avalanche Warp Message can no longer be used to add the `nodeID` to the validator set of `subnetID`
* `remainingBalanceOwner` is the P-Chain owner where leftover \$AVAX from the validator's Balance will be issued to when this validator it is removed from the validator set.
* `disableOwner` is the only P-Chain owner allowed to disable the validator using `DisableL1ValidatorTx`, specified below.
#### `L1ValidatorRegistrationMessage`
The P-Chain can produce an `L1ValidatorRegistrationMessage` for consumers to verify that a validation period has either begun or has been invalidated.
The `L1ValidatorRegistrationMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `registered` | `bool` | 1 byte |
| | | 39 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000002` for this message
* `validationID` identifies the validator for the message
* `registered` is a boolean representing the status of the `validationID`. If true, the `validationID` corresponds to a validator in the current validator set. If false, the `validationID` does not correspond to a validator in the current validator set, and never will in the future.
#### `L1ValidatorWeightMessage`
The P-Chain can consume an `L1ValidatorWeightMessage` through a `SetL1ValidatorWeightTx` to update the weight of an existing validator. The P-Chain can also produce an `L1ValidatorWeightMessage` for consumers to verify that the validator weight update has been effectuated.
The `L1ValidatorWeightMessage` is specified as an `AddressedCall` with the following payload. When sent from the P-Chain, the `sourceChainID` is set to the P-Chain ID, and the `sourceAddress` is set to an empty byte array.
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `nonce` | `uint64` | 8 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 54 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000003` for this message
* `validationID` identifies the validator for the message
* `nonce` is a strictly increasing number that denotes the latest validator weight update and provides replay protection for this transaction
* `weight` is the new `weight` of the validator
### New P-Chain Transaction Types
Both before and after this ACP, to create a Subnet, a `CreateSubnetTx` must be issued on the P-Chain. This transaction includes an `Owner` field which defines the key that today can be used to authorize any validator set additions (`AddSubnetValidatorTx`) or removals (`RemoveSubnetValidatorTx`).
To be considered a permissionless network, or Avalanche Layer 1:
* This `Owner` key must no longer have the ability to modify the validator set.
* New transaction types must support modification of the validator set via Warp messages.
The following new transaction types are introduced on the P-Chain to support this functionality:
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
#### `ConvertSubnetToL1Tx`
To convert a Subnet into an L1, a `ConvertSubnetToL1Tx` must be issued to set the `(chainID, address)` pair that will manage the L1's validator set. The `Owner` key defined in `CreateSubnetTx` must provide a signature to authorize this conversion.
The `ConvertSubnetToL1Tx` specification is:
```go
type PChainOwner struct {
// The threshold number of `Addresses` that must provide a signature in order for
// the `PChainOwner` to be considered valid.
Threshold uint32 `json:"threshold"`
// The 20-byte addresses that are allowed to sign to authenticate a `PChainOwner`.
// Note: It is required for:
// - len(Addresses) == 0 if `Threshold` is 0.
// - len(Addresses) >= `Threshold`
// - The values in Addresses to be sorted in ascending order.
Addresses []ids.ShortID `json:"addresses"`
}
type L1Validator struct {
// NodeID of this validator
NodeID []byte `json:"nodeID"`
// Weight of this validator used when sampling
Weight uint64 `json:"weight"`
// Initial balance for this validator
Balance uint64 `json:"balance"`
// [Signer] is the BLS public key and proof-of-possession for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer signer.ProofOfPossession `json:"signer"`
// Leftover $AVAX from the [Balance] will be issued to this
// owner once it is removed from the validator set.
RemainingBalanceOwner PChainOwner `json:"remainingBalanceOwner"`
// The only owner allowed to disable this validator on the P-Chain.
DisableOwner PChainOwner `json:"disableOwner"`
}
type ConvertSubnetToL1Tx struct {
// Metadata, inputs and outputs
BaseTx
// ID of the Subnet to transform
// Restrictions:
// - Must not be the Primary Network ID
Subnet ids.ID `json:"subnetID"`
// BlockchainID where the validator manager lives
ChainID ids.ID `json:"chainID"`
// Address of the validator manager
Address []byte `json:"address"`
// Initial continuous-fee-paying validators for the L1
Validators []L1Validator `json:"validators"`
// Authorizes this conversion
SubnetAuth verify.Verifiable `json:"subnetAuthorization"`
}
```
After this transaction is accepted, `CreateChainTx` and `AddSubnetValidatorTx` are disabled on the Subnet. The only action that the `Owner` key is able to take is removing Subnet validators with `RemoveSubnetValidatorTx` that had been added using `AddSubnetValidatorTx`. Unless removed by the `Owner` key, any Subnet validators added previously with an `AddSubnetValidatorTx` will continue to validate the Subnet until their [`End`](https://github.com/ava-labs/avalanchego/blob/a1721541754f8ee23502b456af86fea8c766352a/vms/platformvm/txs/validator.go#L27) time is reached. Once all Subnet validators added with `AddSubnetValidatorTx` are no longer in the validator set, the `Owner` key is powerless. `RegisterL1ValidatorTx` and `SetL1ValidatorWeightTx` must be used to manage the L1's validator set.
The `validationID` for validators added through `ConvertSubnetToL1Tx` is defined as the SHA256 hash of the 36 bytes resulting from concatenating the 32 byte `subnetID` with the 4 byte `validatorIndex` (index in the `Validators` array within the transaction).
Once this transaction is accepted, the P-Chain must be willing sign a `SubnetToL1ConversionMessage` with a `conversionID` corresponding to `ConversionData` populated with the values from this transaction.
#### `RegisterL1ValidatorTx`
After a `ConvertSubnetToL1Tx` has been accepted, new validators can only be added by using a `RegisterL1ValidatorTx`. The specification of this transaction is:
```go
type RegisterL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee.
Balance uint64 `json:"balance"`
// [Signer] is a BLS signature proving ownership of the BLS public key specified
// below in `Message` for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer [96]byte `json:"signer"`
// A RegisterL1ValidatorMessage payload
Message warp.Message `json:"message"`
}
```
The `validationID` of validators added via `RegisterL1ValidatorTx` is defined as the SHA256 hash of the `Payload` of the `AddressedCall` in `Message`.
When a `RegisterL1ValidatorTx` is accepted on the P-Chain, the validator is added to the L1's validator set. A `minNonce` field corresponding to the `validationID` will be stored on addition to the validator set (initially set to `0`). This field will be used when validating the `SetL1ValidatorWeightTx` defined below.
This `validationID` will be used for replay protection. Used `validationID`s will be stored on the P-Chain. If a `RegisterL1ValidatorTx`'s `validationID` has already been used, the transaction will be considered invalid. To prevent storing an unbounded number of `validationID`s, the `expiry` of the `RegisterL1ValidatorMessage` is required to be no more than 24 hours in the future of the time the transaction is issued on the P-Chain. Any `validationIDs` corresponding to an expired timestamp can be flushed from the P-Chain's state.
L1s are responsible for defining the procedure on how to retrieve the above information from prospective validators.
An EVM-compatible L1 may choose to implement this step like so:
* Use the number of tokens the user has staked into a smart contract on the L1 to determine the weight of their validator
* Require the user to submit an on-chain transaction with their validator information
* Generate the Warp message
For a `RegisterL1ValidatorTx` to be valid, `Signer` must be a valid proof-of-possession of the `blsPublicKey` defined in the `RegisterL1ValidatorMessage` contained in the transaction.
After a `RegisterL1ValidatorTx` is accepted, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the given `validationID` with `registered` set to `true`. This remains the case until the time at which the validator is removed from the validator set using a `SetL1ValidatorWeightTx`, as described below.
When it is known that a given `validationID` *is not and never will be* registered, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the `validationID` with `registered` set to `false`. This could be the case if the `expiry` time of the message has passed prior to the message being delivered in a `RegisterL1ValidatorTx`, or if the validator was successfully registered and then later removed. This enables the P-Chain to prove to validator managers that a validator has been removed or never added. The P-Chain must refuse to sign any `L1ValidatorRegistrationMessage` where the `validationID` does not correspond to an active validator and the `expiry` is in the future.
#### `SetL1ValidatorWeightTx`
`SetL1ValidatorWeightTx` is used to modify the voting weight of a validator. The specification of this transaction is:
```go
type SetL1ValidatorWeightTx struct {
// Metadata, inputs and outputs
BaseTx
// An L1ValidatorWeightMessage payload
Message warp.Message `json:"message"`
}
```
Applications of this transaction could include:
* Increase the voting weight of a validator if a delegation is made on the L1
* Increase the voting weight of a validator if the stake amount is increased (by staking rewards for example)
* Decrease the voting weight of a misbehaving validator
* Remove an inactive validator
The validation criteria for `L1ValidatorWeightMessage` is:
* `nonce >= minNonce`. Note that `nonce` is not required to be incremented by `1` with each successive validator weight update.
* When `minNonce == MaxUint64`, `nonce` must be `MaxUint64` and `weight` must be `0`. This prevents L1s from being unable to remove `nodeID` in a subsequent transaction.
* If `weight == 0`, the validator being removed must not be the last one in the set. If all validators are removed, there are no valid Warp messages that can be produced to register new validators through `RegisterL1ValidatorMessage`. With no validators, block production will halt and the L1 is unrecoverable. This validation criteria serves as a guardrail against this situation. A future ACP can remove this guardrail as users get more familiar with the new L1 mechanics and tooling matures to fork an L1.
When `weight != 0`, the weight of the validator is updated to `weight` and `minNonce` is updated to `nonce + 1`.
When `weight == 0`, the validator is removed from the validator set. All state related to the validator, including the `minNonce` and `validationID`, are reaped from the P-Chain state. Tracking these post-removal is not required since `validationID` can never be re-initialized due to the replay protection provided by `expiry` in `RegisterL1ValidatorTx`. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that `RemainingBalanceOwner` is specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
Note: There is no explicit `EndTime` for L1 validators added in a `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`. The only time when L1 validators are removed from the L1's validator set is through this transaction when `weight == 0`.
#### `DisableL1ValidatorTx`
L1 validators can use `DisableL1ValidatorTx` to mark their validator as inactive. The specification of this transaction is:
```go
type DisableL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Authorizes this validator to be disabled
DisableAuth verify.Verifiable `json:"disableAuthorization"`
}
```
The `DisableOwner` specified for this validator must sign the transaction. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that both `DisableOwner` and `RemainingBalanceOwner` are specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
For full removal from an L1's validator set, a `SetL1ValidatorWeightTx` must be issued with weight `0`. To do so, a Warp message is required from the L1's validator manager. However, to support the ability to claim the unspent `Balance` for a validator without authorization is critical for failed L1s.
Note that this does not modify an L1's total staking weight. This transaction marks the validator as inactive, but does not remove it from the L1's validator set. Inactive validators can re-activate at any time by increasing their balance with an `IncreaseL1ValidatorBalanceTx`.
L1 creators should be aware that there is no notion of `MinStakeDuration` that is enforced by the P-Chain. It is expected that L1s who choose to enforce a `MinStakeDuration` will lock the validator's Stake for the L1's desired `MinStakeDuration`.
#### `IncreaseL1ValidatorBalanceTx`
L1 validators are required to maintain a non-zero balance used to pay the continuous fee on the P-Chain in order to be considered active. The `IncreaseL1ValidatorBalanceTx` can be used by anybody to add additional \$AVAX to the `Balance` to a validator. The specification of this transaction is:
```go
type IncreaseL1ValidatorBalanceTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee
Balance uint64 `json:"balance"`
}
```
If the validator corresponding to `ValidationID` is currently inactive (`Balance` was exhausted or `DisableL1ValidatorTx` was issued), this transaction will move them back to the active validator set.
Note: The \$AVAX added to `Balance` can be claimed at any time by the validator using `DisableL1ValidatorTx`.
### Bootstrapping L1 Nodes
Bootstrapping a node/validator is the process of securely recreating the latest state of the blockchain locally. At the end of this process, the local state of a node/validator must be in sync with the local state of other virtuous nodes/validators. The node/validator can then verify new incoming transactions and reach consensus with other nodes/validators.
To bootstrap a node/validator, a few critical questions must be answered: How does one discover peers in the network? How does one determine that a discovered peer is honestly participating in the network?
For standalone networks like the Avalanche Primary Network, this is done by connecting to a hardcoded [set](https://github.com/ava-labs/avalanchego/blob/master/genesis/bootstrappers.json) of trusted bootstrappers to then discover new peers. Ethereum calls their set [bootnodes](https://ethereum.org/developers/docs/nodes-and-clients/bootnodes).
Since L1 validators are not required to be Primary Network validators, a list of validator IPs to connect to (the functional bootstrappers of the L1) cannot be provided by simply connecting to the Primary Network validators. However, the Primary Network can enable nodes tracking an L1 to seamlessly connect to the validators by tracking and gossiping L1 validator IPs. L1s will not need to operate and maintain a set of bootstrappers and can rely on the Primary Network for peer discovery.
### Sidebar: L1 Sovereignty
After this ACP is activated, the P-Chain will no longer support staking of any assets other than $AVAX for the Primary Network. The P-Chain will not support the distribution of staking rewards for L1s. All staking-related operations for L1 validation must be managed by the L1's validator manager. The P-Chain simply requires a continuous fee per validator. If an L1 would like to manage their validator's balances on the P-Chain, it can cover the cost for all L1 validators by posting the $AVAX balance on the P-Chain. L1s can implement any mechanism they want to pay the continuous fee charged by the P-Chain for its participants.
The L1 has full ownership over its validator set, not the P-Chain. There are no restrictions on what requirements an L1 can have for validators to join. Any stake that is required to join the L1's validator set is not locked on the P-Chain. If a validator is removed from the L1's validator set via a `SetL1ValidatorWeightTx` with weight `0`, the stake will continue to be locked outside of the P-Chain. How each L1 handles stake associated with the validator is entirely left up to the L1 and can be treated independently to what happens on the P-Chain.
The relationship between the P-Chain and L1s provides a dynamic where L1s can use the P-Chain as an impartial judge to modify parameters (in addition to its existing role of helping to validate incoming Avalanche Warp Messages). If a validator is misbehaving, the L1 validators can collectively generate a BLS multisig to reduce the voting weight of a misbehaving validator. This operation is fully secured by the Avalanche Primary Network (225M $AVAX or $8.325B at the time of writing).
Follow-up ACPs could extend the P-Chain \<-> L1 relationship to include parametrization of the 67% threshold to enable L1s to choose a different threshold based on their security model (e.g. a simple majority of 51%).
### Continuous Fee Mechanism
Every additional validator on the P-Chain adds persistent load to the Avalanche Network. When a validator transaction is issued on the P-Chain, it is charged for the computational cost of the transaction itself but is not charged for the cost of an active validator over the time they are validating on the network (which may be indefinitely). This is a common problem in blockchains, spawning many state rent proposals in the broader blockchain space to address it. The following fee mechanism takes advantage of the fact that each L1 validator uses the same amount of computation and charges each L1 validator the dynamic base fee for every discrete unit of time it is active.
To charge each L1 validator, the notion of a `Balance` is introduced. The `Balance` of a validator will be continuously charged during the time they are active to cover the cost of storing the associated validator properties (BLS key, weight, nonce) in memory and to track IPs (in addition to other services provided by the Primary Network). This `Balance` is initialized with the `RegisterL1ValidatorTx` that added them to the active validator set. `Balance` can be increased at any time using the `IncreaseL1ValidatorBalanceTx`. When this `Balance` reaches `0`, the validator will be considered "inactive" and will no longer participate in validating the L1. Inactive validators can be moved back to the active validator set at any time using the same `IncreaseL1ValidatorBalanceTx`. Once a validator is considered inactive, the P-Chain will remove these properties from memory and only retain them on disk. All messages from that validator will be considered invalid until it is revived using the `IncreaseL1ValidatorBalanceTx`. L1s can reduce the amount of inactive weight by removing inactive validators with the `SetL1ValidatorWeightTx` (`Weight` = 0).
Since each L1 validator is charged the same amount at each point in time, tracking the fees for the entire validator set is straight-forward. The accumulated dynamic base fee for the entire network is tracked in a single uint. This accumulated value should be equal to the fee charged if a validator was active from the time the accumulator was instantiated. The validator set is maintained in a priority queue. A pseudocode implementation of the continuous fee mechanism is provided below.
```python
# Pseudocode
class ValidatorQueue:
def __init__(self, fee_getter):
self.acc = 0
self.queue = PriorityQueue()
self.fee_getter = fee_getter
# At each time period, increment the accumulator and
# pop all validators from the top of the queue that
# ran out of funds.
# Note: The amount of work done in a single block
# should be bounded to prevent a large number of
# validator operations from happening at the same
# time.
def time_elapse(self, t):
self.acc = self.acc + self.fee_getter(t)
while True:
vdr = self.queue.peek()
if vdr.balance < self.acc:
self.queue.pop()
continue
return
# Validator was added
def validator_enter(self, vdr):
vdr.balance = vdr.balance + self.acc
self.queue.add(vdr)
# Validator was removed
def validator_remove(self, vdrNodeID):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance - self.acc
vdr.refund() # Refund [vdr.balance] to [RemainingBalanceOwner]
self.queue.remove()
# Validator's balance was topped up
def validator_increase(self, vdrNodeID, balance):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance + balance
self.queue.add(vdr)
```
#### Fee Algorithm
[ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) proposes a dynamic fee mechanism for transactions on the P-Chain. This mechanism is repurposed with minor modifications for the active L1 validator continuous fee.
At activation, the number of excess active L1 validators $x$ is set to `0`.
The fee rate per second for an active L1 validator is:
$M \cdot \exp\left(\frac{x}{K}\right)$
Where:
* $M$ is the minimum price for an active L1 validator
* $\exp\left(x\right)$ is an approximation of $e^x$ following the EIP-4844 specification
```python
# Approximates factor * e ** (numerator / denominator) using Taylor expansion
def fake_exponential(factor: int, numerator: int, denominator: int) -> int:
i = 1
output = 0
numerator_accum = factor * denominator
while numerator_accum > 0:
output += numerator_accum
numerator_accum = (numerator_accum * numerator) // (denominator * i)
i += 1
return output // denominator
```
* $K$ is a constant to control the rate of change for the L1 validator price
After every second, $x$ will be updated:
$x = \max(x + (V - T), 0)$
Where:
* $V$ is the number of active L1 validators
* $T$ is the target number of active L1 validators
Whenever $x$ increases by $K$, the price per active L1 validator increases by a factor of `~2.7`. If the price per active L1 validator gets too expensive, some active L1 validators will exit the active validator set, decreasing $x$, dropping the price. The price per active L1 validator constantly adjusts to make sure that, on average, the P-Chain has no more than $T$ active L1 validators.
#### Block Processing
Before processing the transactions inside a block, all validators that no longer have a sufficient (non-zero) balance are deactivated.
After processing the transactions inside a block, all validators that do not have a sufficient balance for the next second are deactivated.
##### Block Timestamp Validity Change
To ensure that validators are charged accurately, blocks are only considered valid if advancing the chain times would not cause a validator to have a negative balance.
This upholds the expectation that the number of L1 validators remains constant between blocks.
The block building protocol is modified to account for this change by first checking if the wall clock time removes any validator due to a lack of funds. If the wall clock time does not remove any L1 validators, the wall clock time is used to build the block. If it does, the time at which the first validator gets removed is used.
##### Fee Calculation
The total validator fee assessed in $\Delta t$ is:
```python
# Calculate the fee to charge over Δt
def cost_over_time(V:int, T:int, x:int, Δt: int) -> int:
cost = 0
for _ in range(Δt):
x = max(x + V - T, 0)
cost += fake_exponential(M, x, K)
return cost
```
#### Parameters
The parameters at activation are:
| Parameter | Definition | Value |
| --------- | ------------------------------------------- | ---------------- |
| $T$ | target number of validators | 10\_000 |
| $C$ | capacity number of validators | 20\_000 |
| $M$ | minimum fee rate | 512 nAVAX/s |
| $K$ | constant to control the rate of fee changes | 1\_246\_488\_515 |
An $M$ of 512 nAVAX/s equates to \~1.33 AVAX/month to run an L1 validator, so long as the total number of continuous-fee-paying L1 validators stays at or below $T$.
$K$ was chosen to set the maximum fee doubling rate to \~24 hours. This is in the extreme case that the network has $C$ validators for prolonged periods of time; if the network has $T$+1 validators for example, the fee rate would double every \~27 years.
A future ACP can adjust the parameters to increase $T$, reduce $M$, and/or modify $K$.
#### User Experience
L1 validators are continuously charged a fee, albeit a small one. This poses a challenge for L1 validators: How do they maintain the balance over time?
Node clients should expose an API to track how much balance is remaining in the validator's account. This will provide a way for L1 validators to track how quickly it is going down and top-up when needed. A nice byproduct of the above design is the balance in the validator's account is claimable. This means users can top-up as much \$AVAX as they want and rest-assured knowing they can always retrieve it if there is an excessive amount.
The expectation is that most users will not interact with node clients or track when or how much they need to top-up their validator account. Wallet providers will abstract away most of this process. For users who desire more convenience, L1-as-a-Service providers will abstract away all of this process.
## Backwards Compatibility
This new design for Subnets proposes a large rework to all L1-related mechanics. Rollout should be done on a going-forward basis to not cause any service disruption for live Subnets. All current Subnet validators will be able to continue validating both the Primary Network and whatever Subnets they are validating.
Any state execution changes must be coordinated through a mandatory upgrade. Implementors must take care to continue to verify the existing ruleset until the upgrade is activated. After activation, nodes should verify the new ruleset. Implementors must take care to only verify the presence of 2000 \$AVAX prior to activation.
### Deactivated Transactions
* P-Chain
* `TransformSubnetTx`
After this ACP is activated, Elastic Subnets will be disabled. `TransformSubnetTx` will not be accepted post-activation. As there are no Mainnet Elastic Subnets, there should be no production impact with this deactivation.
### New Transactions
* P-Chain
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
## Reference Implementation
ACP-77 was implemented and will be merged into AvalancheGo behind the `Etna` upgrade flag. The full body of work can be found tagged with the `acp77` label [here](https://github.com/ava-labs/avalanchego/issues?q=sort%3Aupdated-desc+label%3Aacp77).
Since Etna is not yet activated, all new transactions introduced in ACP-77 will be rejected by AvalancheGo. If any modifications are made to ACP-77 as part of the ACP process, the implementation must be updated prior to activation.
## Security Considerations
This ACP introduces Avalanche Layer 1s, a new network type that costs significantly less than Avalanche Subnets. This can lead to a large increase in the number of networks and, by extension, the number of validators. Each additional validator adds consistent RAM usage to the P-Chain. However, this should be appropriately metered by the continuous fee mechanism outlined above.
With the sovereignty L1s have from the P-Chain, L1 staking tokens are not locked on the P-Chain. This poses a security consideration for L1 validators: Malicious chains can choose to remove validators at will and take any funds that the validator has locked on the L1. The P-Chain only provides the guarantee that L1 validators can retrieve the remaining \$AVAX Balance for their validator via a `DisableL1ValidatorTx`. Any assets on the L1 is entirely under the purview of the L1. The onus is on L1 validators to vet the L1's security for any assets transferred onto the L1.
With a long window of expiry (24 hours) for the Warp message in `RegisterL1ValidatorTx`, spam of validator registration could lead to high memory pressure on the P-Chain. A future ACP can reduce the window of expiry if 24 hours proves to be a problem.
NodeIDs can be added to an L1's validator set involuntarily. However, it is important to note that any stake/rewards are *not* at risk. For a node operator who was added to a validator set involuntarily, they would only need to generate a new NodeID via key rotation as there is no lock-up of any stake to create a NodeID. This is an explicit tradeoff for easier on-boarding of NodeIDs. This mirrors the Primary Network validators guarantee of no stake/rewards at risk.
The continuous fee mechanism outlined above does not apply to inactive L1 validators since they are not stored in memory. However, inactive L1 validators are persisted on disk which can lead to persistent P-Chain state growth. A future ACP can introduce a mechanism to decrease the rate of P-Chain state growth or provide a state expiry path to reduce the amount of P-Chain state.
## Acknowledgements
Special thanks to [@StephenButtolph](https://github.com/StephenButtolph), [@aaronbuchwald](https://github.com/aaronbuchwald), and [@patrick-ogrady](https://github.com/patrick-ogrady) for their feedback on these ideas. Thank you to the broader Ava Labs Platform Engineering Group for their feedback on this ACP prior to publication.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-83: Dynamic Multidimensional Fees
URL: /docs/acps/83-dynamic-multidimensional-fees
Details for Avalanche Community Proposal 83: Dynamic Multidimensional Fees
| ACP | 83 |
| :---------------- | :------------------------------------------------------------------------------------------------ |
| **Title** | Dynamic multidimensional fees for P-chain and X-chain |
| **Author(s)** | Alberto Benegiamo ([@abi87](https://github.com/abi87)) |
| **Status** | Stale |
| **Track** | Standards |
| **Superseded-By** | [ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) |
## Abstract
Introduce a dynamic and multidimensional fees scheme for the P-chain and X-chain.
Dynamic fees helps to preserve the stability of the chain as it provides a feedback mechanism that increases the cost of resources when the network operates above its target utilization.
Multidimensional fees ensures that high demand for orthogonal resources does not drive up the price of underutilized resources. For example, networks provide and consume orthogonal resources including, but not limited to, bandwidth, chain state, read/write throughput, and CPU. By independently metering each resource, they can be granularly priced and stay closer to optimal resource utilization.
## Motivation
The P-Chain and X-Chain currently have fixed fees and in some cases those fees are fixed to zero.
This makes transaction issuance predictable, but does not provide feedback mechanism to preserve chain stability under high load. In contrast, the C-Chain, which has the highest and most regular load among the chains on the Primary Network, already supports dynamic fees. This ACP proposes to introduce a similar dynamic fee mechanism for the P-Chain and X-Chain to further improve the Primary Network's stability and resilience under load.
However, unlike the C-Chain, we propose a multidimensional fee scheme with an exponential update rule for each fee dimension. The [HyperSDK](https://github.com/ava-labs/hypersdk) already utilizes a multidimensional fee scheme with optional priority fees and its efficiency is backed by [academic research](https://arxiv.org/abs/2208.07919).
Finally, we split the fee into two parts: a `base fee` and a `priority fee`. The `base fee` is calculated by the network each block to accurately price each resource at a given point in time. Whatever amount greater than the base fee is burnt is treated as the `priority fee` to prioritize faster transaction inclusion.
## Specification
We introduce the multidimensional scheme first and then how to apply the dynamic fee update rule for each fee dimension. Finally we list the new block verification rules, valid once the new fee scheme activates.
### Multidimensional scheme components
We define four fee dimensions, `Bandwidth`, `Reads`, `Writes`, `Compute`, to describe transactions complexity. In more details:
* `Bandwidth` measures the transaction size in bytes, as encoded by the AvalancheGo codec. Byte length is a proxy for the network resources needed to disseminate the transaction.
* `Reads` measures the number of DB reads needed to verify the transactions. DB reads include UTXOs reads and any other state quantity relevant for the specific transaction.
* `Writes` measures the number of DB writes following the transaction verification. DB writes include UTXOs generated as outputs of the transactions and any other state quantity relevant for the specific transaction.
* `Compute` measures the number of signatures to be verified, including UTXOs ones and those related to authorization of specific operations.
For each fee dimension $i$, we define:
* *fee rate* $r_i$ as the price, denominated in AVAX, to be paid for a transaction with complexity $u_i$ along the fee dimension $i$.
* *base fee* as the minimal fee needed to accept a transaction. Base fee is given be the formula
$base \ fee = \sum_{i=0}^3 r_i \times u_i$
* *priority fee* as an optional fee paid on top of the base fee to speed up the transaction inclusion in a block.
### Dynamic scheme components
Fee rates are updated in time, to allow a fee increase when network is getting congested. Each new block is a potential source of congestion, as its transactions carry complexity that each validator must process to verify and eventually accept the block. The more complexity carries a block, and the more rapidly blocks are produced, the higher the congestion.
We seek a scheme that rapidly increases the fees when blocks complexity goes above a defined threshold and that equally rapidly decreases the fees once complexity goes down (because blocks carry less/simpler transactions, or because they are produced more slowly). We define the desired threshold as a *target complexity rate* $T$: we would want to process every second a block whose complexity is $T$. Any complexity more than that causes some congestion that we want to penalize via fees.
In order to update fees rates we track, per each block and each fee dimension, a parameter called cumulative excess complexity. Fee rates applied to a block will be defined in terms of cumulative excess complexity as we show in the following.
Suppose that a block $B_t$ is the current chain tip. $B_t$ has the following features:
* $t$ is its timestamp.
* $\Delta C_t$ is the cumulative excess complexity along fee dimension $i$.
Say a new block $B_{t + \Delta T}$ is built on top of $B$, with the following features:
* $t + \Delta T$ is its timestamp
* $C_{t + \Delta T}$ is its complexity along fee dimension $i$.
Then the fee rate $r_{t + \Delta T}$ applied for the block $B_{t + \Delta T}$ along dimension $i$ will be:
$r_{t + \Delta T} = r^{min} \times e^{\frac{max(0, \Delta C_t - T \times \Delta T)}{Denom}}$
where
* $r^{min}$ is the minimal fee rate along fee dimension $i$
* $T$ is the target complexity rate along fee dimension $i$
* $Denom$ is a normalization constant for the fee dimension $i$
Moreover, once the block $B_{t + \Delta T}$ is accepted, the cumulative excess complexity is updated as follows:
$\Delta C_{t + \Delta T} = max\large(0, \Delta C_{t} - T \times \Delta T\large) + C_{t + \Delta T}$
The fee rate update formula guarantees that fee rates increase if incoming blocks are complex (large $C_{t + \Delta T}$) and if blocks are emitted rapidly (small $\Delta T$). Symmetrically, fee rates decrease to the minimum if incoming blocks are less complex and if blocks are produced less frequently.\
The update formula has a few paramenters to be tuned, independently, for each fee dimension. We defer discussion about tuning to the [implementation section](#tuning-the-update-formula).
## Block verification rules
Upon activation of the dynamic multidimensional fees scheme we modify block processing as follows:
* **Bound block complexity**. For each fee dimension $i$, we define a *maximal block complexity* $Max$. A block is only valid if the block complexity $C$ is less than the maximum block complexity: $C \leq Max$.
* **Verify transaction fee**. When verifying each transaction in a block, we confirm that it can cover its own base fee. Note that both base fee and optional priority fees are burned.
## User Experience
### How will the wallets estimate the fees?
AvalancheGo nodes will provide new APIs exposing the current and expected fee rates, as they are likely to change block by block. Wallets can then use the fees rates to select UTXOs to pay the transaction fees. Moreover, the AvalancheGo implementation proposed above offers a `fees.Calculator` struct that can be reused by wallets and downstream projects to evaluate calculate fees.
### How will wallets be able to re-issue Txs at a higher fee?
Wallets should be able to simply re-issue the transaction since current AvalancheGo implementation drops mempool transactions whose fee rate is lower than current one. More specifically, a transaction may be valid the moment it enters the mempool and it won’t be re-verified as long as it stays in there. However, as soon as the transaction is selected to be included in the next block, it is re-verified against the latest preferred tip. If fees are not enough by this time, the transaction is dropped and the wallet can simply re-issue it at a higher fee, or wait for the fee rate to go down. Note that priority fees offer some buffer space against an increase in the fee rate. A transaction paying just the base fee will be evicted from the mempool in the face of a fee rate increase, while a transaction paying some extra priority fee may have enough buffer room to stay valid after some amount of fee increase.
### How does priority fees guarantee a faster block inclusion?
AvalancheGo mempool will be restructured to order transactions by priority fees. Transactions paying priority fees will be selected for block inclusion first, without violating any spend dependency.
## Backwards Compatibility
Modifying the fee scheme for P-Chain and X-Chain requires a mandatory upgrade for activation. Moreover, wallets must be modified to properly handle the new fee scheme once activated.
## Reference Implementation
The implementation is split across multiple PRs:
* P-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2707](https://github.com/ava-labs/avalanchego/issues/2707)
* X-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2708](https://github.com/ava-labs/avalanchego/issues/2708)
A very important implementation step is tuning the update formula parameters for each chain and each fee dimension. We show here the principles we followed for tuning and a simulation based on historical data.
### Tuning the update formula
The basic idea is to measure the complexity of blocks already accepted and derive the parameters from it. You can find the historical data in [this repo](https://github.com/abi87/complexities).\
To simplify the exposition I am purposefully ignoring chain specifics (like P-chain proposal blocks). We can account for chain specifics while processing the historical data. Here are the principles:
* **Target block complexity rate $T$**: calculate the distribution of block complexity and pick a high enough quantile.
* **Max block complexity $Max$**: this is probably the trickiest parameter to set.
Historically we had [pretty big transactions](https://subnets.avax.network/p-chain/tx/27pjHPRCvd3zaoQUYMesqtkVfZ188uP93zetNSqk3kSH1WjED1) (more than $1.000$ referenced utxos). Setting a max block complexity so high that these big transactions are allowed is akin to setting no complexity cap.
On the other side, we still want to allow, even encourage, UTXO consolidation, so we may want to allow transactions [like this](https://subnets.avax.network/p-chain/tx/2LxyHzbi2AGJ4GAcHXth6pj5DwVLWeVmog2SAfh4WrqSBdENhV).
A principled way to set max block complexity may be the following:
* calculate the target block complexity rate (see previous point)
* calculate the median time elapsed among consecutive blocks
* The product of these two quantities should gives us something like a target block complexity.
* Set the max block complexity to say $\times 50$ the target value.
* **Normalization coefficient $Denom$**: I suggest we size it as follows:
* Find the largest historical peak, i.e. the sequence of consecutive blocks which contained the most complexity in the shortest period of time
* Tune $Denom$ so that it would cause a $\times 10000$ increase in the fee rate for such a peak. This increase would push fees from the milliAVAX we normally pay under stable network condition up to tens of AVAX.
* **Minimal fee rates $r^{min}$**: we could size them so that transactions fees do not change very much with respect to the currently fixed values.
We simulate below how the update formula would behave on an peak period from Avalanche mainnet.
***
## Specification
Note: The following is pseudocode.
### P2P
#### Aggregation
```diff
+ message GetAcceptanceSignatureRequest {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes block_id = 3;
+ }
```
The `GetAcceptanceSignatureRequest` message is sent to a peer to request their signature for a given block id.
```diff
+ message GetAcceptanceSignatureResponse {
+ bytes chain_id = 1;
+ uint32 request_id = 2;
+ bytes bls_signature = 3;
+ }
```
`GetAcceptanceSignatureResponse` is sent to a peer as a response for `GetAcceptanceSignatureRequest`. `bls_signature` is the peer’s signature using their registered primary network BLS staking key over the requested `block_id`. An empty `bls_signature` field indicates that the block was not accepted yet.
## Security Considerations
Nodes that bootstrap using state sync may not have the entire history of the
P-Chain and therefore will not be able to provide the entire history for a block
that is referenced in a block that they propose. This would be needed to unblock a node that is attempting to fast-forward their P-Chain, as they require the entire ancestry between their current accepted tip and the block they are attempting to forward to. It is assumed that nodes will have some minimum amount of recent state so that the requester can eventually be unblocked by retrying, as only one node with the requested ancestry is required to unblock the requester.
An alternative is to make a churn assumption and validate the proposed block's proof with a stale validator set to avoid complexity, but this introduces more security concerns.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-77: Reinventing Subnets
URL: /docs/acps/77-reinventing-subnets
Details for Avalanche Community Proposal 77: Reinventing Subnets
| ACP | 77 |
| :------------ | :-------------------------------------------------------------------------------------------------------- |
| **Title** | Reinventing Subnets |
| **Author(s)** | Dhruba Basu ([@dhrubabasu](https://github.com/dhrubabasu)) |
| **Status** | Activated ([Discussion](https://github.com/avalanche-foundation/ACPs/discussions/78)) |
| **Track** | Standards |
| **Replaces** | [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) |
## Abstract
Overhaul Subnet creation and management to unlock increased flexibility for Subnet creators by:
* Separating Subnet validators from Primary Network validators (Primary Network Partial Sync, Removal of 2000 \$AVAX requirement)
* Moving ownership of Subnet validator set management from P-Chain to Subnets (ERC-20/ERC-721/Arbitrary Staking, Staking Reward Management)
* Introducing a continuous P-Chain fee mechanism for Subnet validators (Continuous Subnet Staking)
This ACP supersedes [ACP-13](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/13-subnet-only-validators/README.md) and borrows some of its language.
## Motivation
Each node operator must stake at least 2000 $AVAX ($70k at time of writing) to first become a Primary Network validator before they qualify to become a Subnet validator. Most Subnets aim to launch with at least 8 Subnet validators, which requires staking 16000 $AVAX ($560k at time of writing). All Subnet validators, to satisfy their role as Primary Network validators, must also [allocate 8 AWS vCPU, 16 GB RAM, and 1 TB storage](https://github.com/ava-labs/avalanchego/blob/master/README.md#installation) to sync the entire Primary Network (X-Chain, P-Chain, and C-Chain) and participate in its consensus, in addition to whatever resources are required for each Subnet they are validating.
Regulated entities that are prohibited from validating permissionless, smart contract-enabled blockchains (like the C-Chain) cannot launch a Subnet because they cannot opt-out of Primary Network Validation. This deployment blocker prevents a large cohort of Real World Asset (RWA) issuers from bringing unique, valuable tokens to the Avalanche Ecosystem (that could move between C-Chain \<-> Subnets using Avalanche Warp Messaging/Teleporter).
A widely validated Subnet that is not properly metered could destabilize the Primary Network if usage spikes unexpectedly. Underprovisioned Primary Network validators running such a Subnet may exit with an OOM exception, see degraded disk performance, or find it difficult to allocate CPU time to P/X/C-Chain validation. The inverse also holds for Subnets with the Primary Network (where some undefined behavior could bring a Subnet offline).
Although the fee paid to the Primary Network to operate a Subnet does not go up with the amount of activity on the Subnet, the fixed, upfront cost of setting up a Subnet validator on the Primary Network deters new projects that prefer smaller, even variable, costs until demand is observed. *Unlike L2s that pay some increasing fee (usually denominated in units per transaction byte) to an external chain for data availability and security as activity scales, Subnets provide their own security/data availability and the only cost operators must pay from processing more activity is the hardware cost of supporting additional load.*
Elastic Subnets, introduced in [Banff](https://medium.com/avalancheavax/banff-elastic-subnets-44042f41e34c), enabled Subnet creators to activate Proof-of-Stake validation and uptime-based rewards using their own token. However, this token is required to be an ANT (created on the X-Chain) and locked on the P-Chain. All staking rewards were distributed on the P-Chain with the reward curve being defined in the `TransformSubnetTx` and, once set, was unable to be modified.
With no Elastic Subnets live on Mainnet, it is clear that Permissionless Subnets as they stand today could be more desirable. There are many successful Permissioned Subnets in production but many Subnet creators have raised the above as points of concern. In summary, the Avalanche community could benefit from a more flexible and affordable mechanism to launch Permissionless Subnets.
### A Note on Nomenclature
Avalanche Subnets are subnetworks validated by a subset of the Primary Network validator set. The new network creation flow outlined in this ACP does not require any intersection between the new network's validator set and the Primary Network's validator set. Moreover, the new networks have greater functionality and sovereignty than Subnets. To distinguish between these two kinds of networks, the community has been referring to these new networks as *Avalanche Layer 1s*, or L1s for short.
All networks created through the old network creation flow will continue to be referred to as Avalanche Subnets.
## Specification
At a high-level, L1s can manage their validator sets externally to the P-Chain by setting the blockchain ID and address of their *validator manager*. The P-Chain will consume Warp messages that modify the L1's validator set. To confirm modification of the L1's validator set, the P-Chain will also produce Warp messages. L1 validators are not required to validate the Primary Network, and do not have the same 2000 $AVAX stake requirement that Subnet validators have. To maintain an active L1 validator, a continuous fee denominated in $AVAX is assessed. L1 validators are only required to sync the P-Chain (not X/C-Chain) in order to track validator set changes and support cross-L1 communication.
### P-Chain Warp Message Payloads
To enable management of an L1's validator set externally to the P-Chain, Warp message verification will be added to the [`PlatformVM`](https://github.com/ava-labs/avalanchego/tree/master/vms/platformvm). For a Warp message to be considered valid by the P-Chain, at least 67% of the `sourceChainID`'s weight must have participated in the aggregate BLS signature. This is equivalent to the threshold set for the C-Chain. A future ACP may be proposed to support modification of this threshold on a per-L1 basis.
The following Warp message payloads are introduced on the P-Chain:
* `SubnetToL1ConversionMessage`
* `RegisterL1ValidatorMessage`
* `L1ValidatorRegistrationMessage`
* `L1ValidatorWeightMessage`
The method of requesting signatures for these messages is left unspecified. A viable option for supporting this functionality is laid out in [ACP-118](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/118-warp-signature-request/README.md) with the `SignatureRequest` message.
All node IDs contained within the message specifications are represented as variable length arrays such that they can support new node IDs types should the P-Chain add support for them in the future.
The serialization of each of these messages is as follows.
#### `SubnetToL1ConversionMessage`
The P-Chain can produce a `SubnetToL1ConversionMessage` for consumers (i.e. validator managers) to be aware of the initial validator set.
The following serialization is defined as the `ValidatorData`:
| Field | Type | Size |
| -------------: | ---------: | -----------------------: |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 60 + len(`nodeID`) bytes |
The following serialization is defined as the `ConversionData`:
| Field | Type | Size |
| ---------------: | ----------------: | ---------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `managerChainID` | `[32]byte` | 32 bytes |
| `managerAddress` | `[]byte` | 4 + len(`managerAddress`) bytes |
| `validators` | `[]ValidatorData` | 4 + sum(`validatorLengths`) bytes |
| | | 74 + len(`managerAddress`) + sum(`validatorLengths`) bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `sum(validatorLengths)` is the sum of the lengths of `ValidatorData` serializations included in `validators`.
* `subnetID` identifies the Subnet that is being converted to an L1 (described further below).
* `managerChainID` and `managerAddress` identify the validator manager for the newly created L1. This is the (blockchain ID, address) tuple allowed to send Warp messages to modify the L1's validator set.
* `validators` are the initial continuous-fee-paying validators for the given L1.
The `SubnetToL1ConversionMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `conversionID` | `[32]byte` | 32 bytes |
| | | 38 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000000` for this message
* `conversionID` is the SHA256 hash of the `ConversionData` from a given `ConvertSubnetToL1Tx`
#### `RegisterL1ValidatorMessage`
The P-Chain can consume a `RegisterL1ValidatorMessage` from validator managers through a `RegisterL1ValidatorTx` to register an addition to the L1's validator set.
The following is the serialization of a `PChainOwner`:
| Field | Type | Size |
| ----------: | -----------: | ---------------------------------: |
| `threshold` | `uint32` | 4 bytes |
| `addresses` | `[][20]byte` | 4 + len(`addresses`) \\\* 20 bytes |
| | | 8 + len(`addresses`) \\\* 20 bytes |
* `threshold` is the number of `addresses` that must provide a signature for the `PChainOwner` to authorize an action.
* Validation criteria:
* If `threshold` is `0`, `addresses` must be empty
* `threshold` \<= len(`addresses`)
* Entries of `addresses` must be unique and sorted in ascending order
The `RegisterL1ValidatorMessage` is specified as an `AddressedCall` with a payload of:
| Field | Type | Size |
| ----------------------: | ------------: | --------------------------------------------------------------------------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `subnetID` | `[32]byte` | 32 bytes |
| `nodeID` | `[]byte` | 4 + len(`nodeID`) bytes |
| `blsPublicKey` | `[48]byte` | 48 bytes |
| `expiry` | `uint64` | 8 bytes |
| `remainingBalanceOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `disableOwner` | `PChainOwner` | 8 + len(`addresses`) \\\* 20 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 122 + len(`nodeID`) + (len(`addresses1`) + len(`addresses2`)) \\\* 20 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000001` for this payload
* `subnetID`, `nodeID`, `weight`, and `blsPublicKey` are for the validator being added
* `expiry` is the time at which this message becomes invalid. As of a P-Chain timestamp `>= expiry`, this Avalanche Warp Message can no longer be used to add the `nodeID` to the validator set of `subnetID`
* `remainingBalanceOwner` is the P-Chain owner where leftover \$AVAX from the validator's Balance will be issued to when this validator it is removed from the validator set.
* `disableOwner` is the only P-Chain owner allowed to disable the validator using `DisableL1ValidatorTx`, specified below.
#### `L1ValidatorRegistrationMessage`
The P-Chain can produce an `L1ValidatorRegistrationMessage` for consumers to verify that a validation period has either begun or has been invalidated.
The `L1ValidatorRegistrationMessage` is specified as an `AddressedCall` with `sourceChainID` set to the P-Chain ID, the `sourceAddress` set to an empty byte array, and a payload of:
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `registered` | `bool` | 1 byte |
| | | 39 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000002` for this message
* `validationID` identifies the validator for the message
* `registered` is a boolean representing the status of the `validationID`. If true, the `validationID` corresponds to a validator in the current validator set. If false, the `validationID` does not correspond to a validator in the current validator set, and never will in the future.
#### `L1ValidatorWeightMessage`
The P-Chain can consume an `L1ValidatorWeightMessage` through a `SetL1ValidatorWeightTx` to update the weight of an existing validator. The P-Chain can also produce an `L1ValidatorWeightMessage` for consumers to verify that the validator weight update has been effectuated.
The `L1ValidatorWeightMessage` is specified as an `AddressedCall` with the following payload. When sent from the P-Chain, the `sourceChainID` is set to the P-Chain ID, and the `sourceAddress` is set to an empty byte array.
| Field | Type | Size |
| -------------: | ---------: | -------: |
| `codecID` | `uint16` | 2 bytes |
| `typeID` | `uint32` | 4 bytes |
| `validationID` | `[32]byte` | 32 bytes |
| `nonce` | `uint64` | 8 bytes |
| `weight` | `uint64` | 8 bytes |
| | | 54 bytes |
* `codecID` is the codec version used to serialize the payload, and is hardcoded to `0x0000`
* `typeID` is the payload type identifier and is `0x00000003` for this message
* `validationID` identifies the validator for the message
* `nonce` is a strictly increasing number that denotes the latest validator weight update and provides replay protection for this transaction
* `weight` is the new `weight` of the validator
### New P-Chain Transaction Types
Both before and after this ACP, to create a Subnet, a `CreateSubnetTx` must be issued on the P-Chain. This transaction includes an `Owner` field which defines the key that today can be used to authorize any validator set additions (`AddSubnetValidatorTx`) or removals (`RemoveSubnetValidatorTx`).
To be considered a permissionless network, or Avalanche Layer 1:
* This `Owner` key must no longer have the ability to modify the validator set.
* New transaction types must support modification of the validator set via Warp messages.
The following new transaction types are introduced on the P-Chain to support this functionality:
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
#### `ConvertSubnetToL1Tx`
To convert a Subnet into an L1, a `ConvertSubnetToL1Tx` must be issued to set the `(chainID, address)` pair that will manage the L1's validator set. The `Owner` key defined in `CreateSubnetTx` must provide a signature to authorize this conversion.
The `ConvertSubnetToL1Tx` specification is:
```go
type PChainOwner struct {
// The threshold number of `Addresses` that must provide a signature in order for
// the `PChainOwner` to be considered valid.
Threshold uint32 `json:"threshold"`
// The 20-byte addresses that are allowed to sign to authenticate a `PChainOwner`.
// Note: It is required for:
// - len(Addresses) == 0 if `Threshold` is 0.
// - len(Addresses) >= `Threshold`
// - The values in Addresses to be sorted in ascending order.
Addresses []ids.ShortID `json:"addresses"`
}
type L1Validator struct {
// NodeID of this validator
NodeID []byte `json:"nodeID"`
// Weight of this validator used when sampling
Weight uint64 `json:"weight"`
// Initial balance for this validator
Balance uint64 `json:"balance"`
// [Signer] is the BLS public key and proof-of-possession for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer signer.ProofOfPossession `json:"signer"`
// Leftover $AVAX from the [Balance] will be issued to this
// owner once it is removed from the validator set.
RemainingBalanceOwner PChainOwner `json:"remainingBalanceOwner"`
// The only owner allowed to disable this validator on the P-Chain.
DisableOwner PChainOwner `json:"disableOwner"`
}
type ConvertSubnetToL1Tx struct {
// Metadata, inputs and outputs
BaseTx
// ID of the Subnet to transform
// Restrictions:
// - Must not be the Primary Network ID
Subnet ids.ID `json:"subnetID"`
// BlockchainID where the validator manager lives
ChainID ids.ID `json:"chainID"`
// Address of the validator manager
Address []byte `json:"address"`
// Initial continuous-fee-paying validators for the L1
Validators []L1Validator `json:"validators"`
// Authorizes this conversion
SubnetAuth verify.Verifiable `json:"subnetAuthorization"`
}
```
After this transaction is accepted, `CreateChainTx` and `AddSubnetValidatorTx` are disabled on the Subnet. The only action that the `Owner` key is able to take is removing Subnet validators with `RemoveSubnetValidatorTx` that had been added using `AddSubnetValidatorTx`. Unless removed by the `Owner` key, any Subnet validators added previously with an `AddSubnetValidatorTx` will continue to validate the Subnet until their [`End`](https://github.com/ava-labs/avalanchego/blob/a1721541754f8ee23502b456af86fea8c766352a/vms/platformvm/txs/validator.go#L27) time is reached. Once all Subnet validators added with `AddSubnetValidatorTx` are no longer in the validator set, the `Owner` key is powerless. `RegisterL1ValidatorTx` and `SetL1ValidatorWeightTx` must be used to manage the L1's validator set.
The `validationID` for validators added through `ConvertSubnetToL1Tx` is defined as the SHA256 hash of the 36 bytes resulting from concatenating the 32 byte `subnetID` with the 4 byte `validatorIndex` (index in the `Validators` array within the transaction).
Once this transaction is accepted, the P-Chain must be willing sign a `SubnetToL1ConversionMessage` with a `conversionID` corresponding to `ConversionData` populated with the values from this transaction.
#### `RegisterL1ValidatorTx`
After a `ConvertSubnetToL1Tx` has been accepted, new validators can only be added by using a `RegisterL1ValidatorTx`. The specification of this transaction is:
```go
type RegisterL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee.
Balance uint64 `json:"balance"`
// [Signer] is a BLS signature proving ownership of the BLS public key specified
// below in `Message` for this validator.
// Note: We do not enforce that the BLS key is unique across all validators.
// This means that validators can share a key if they so choose.
// However, a NodeID + L1 does uniquely map to a BLS key
Signer [96]byte `json:"signer"`
// A RegisterL1ValidatorMessage payload
Message warp.Message `json:"message"`
}
```
The `validationID` of validators added via `RegisterL1ValidatorTx` is defined as the SHA256 hash of the `Payload` of the `AddressedCall` in `Message`.
When a `RegisterL1ValidatorTx` is accepted on the P-Chain, the validator is added to the L1's validator set. A `minNonce` field corresponding to the `validationID` will be stored on addition to the validator set (initially set to `0`). This field will be used when validating the `SetL1ValidatorWeightTx` defined below.
This `validationID` will be used for replay protection. Used `validationID`s will be stored on the P-Chain. If a `RegisterL1ValidatorTx`'s `validationID` has already been used, the transaction will be considered invalid. To prevent storing an unbounded number of `validationID`s, the `expiry` of the `RegisterL1ValidatorMessage` is required to be no more than 24 hours in the future of the time the transaction is issued on the P-Chain. Any `validationIDs` corresponding to an expired timestamp can be flushed from the P-Chain's state.
L1s are responsible for defining the procedure on how to retrieve the above information from prospective validators.
An EVM-compatible L1 may choose to implement this step like so:
* Use the number of tokens the user has staked into a smart contract on the L1 to determine the weight of their validator
* Require the user to submit an on-chain transaction with their validator information
* Generate the Warp message
For a `RegisterL1ValidatorTx` to be valid, `Signer` must be a valid proof-of-possession of the `blsPublicKey` defined in the `RegisterL1ValidatorMessage` contained in the transaction.
After a `RegisterL1ValidatorTx` is accepted, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the given `validationID` with `registered` set to `true`. This remains the case until the time at which the validator is removed from the validator set using a `SetL1ValidatorWeightTx`, as described below.
When it is known that a given `validationID` *is not and never will be* registered, the P-Chain must be willing to sign an `L1ValidatorRegistrationMessage` for the `validationID` with `registered` set to `false`. This could be the case if the `expiry` time of the message has passed prior to the message being delivered in a `RegisterL1ValidatorTx`, or if the validator was successfully registered and then later removed. This enables the P-Chain to prove to validator managers that a validator has been removed or never added. The P-Chain must refuse to sign any `L1ValidatorRegistrationMessage` where the `validationID` does not correspond to an active validator and the `expiry` is in the future.
#### `SetL1ValidatorWeightTx`
`SetL1ValidatorWeightTx` is used to modify the voting weight of a validator. The specification of this transaction is:
```go
type SetL1ValidatorWeightTx struct {
// Metadata, inputs and outputs
BaseTx
// An L1ValidatorWeightMessage payload
Message warp.Message `json:"message"`
}
```
Applications of this transaction could include:
* Increase the voting weight of a validator if a delegation is made on the L1
* Increase the voting weight of a validator if the stake amount is increased (by staking rewards for example)
* Decrease the voting weight of a misbehaving validator
* Remove an inactive validator
The validation criteria for `L1ValidatorWeightMessage` is:
* `nonce >= minNonce`. Note that `nonce` is not required to be incremented by `1` with each successive validator weight update.
* When `minNonce == MaxUint64`, `nonce` must be `MaxUint64` and `weight` must be `0`. This prevents L1s from being unable to remove `nodeID` in a subsequent transaction.
* If `weight == 0`, the validator being removed must not be the last one in the set. If all validators are removed, there are no valid Warp messages that can be produced to register new validators through `RegisterL1ValidatorMessage`. With no validators, block production will halt and the L1 is unrecoverable. This validation criteria serves as a guardrail against this situation. A future ACP can remove this guardrail as users get more familiar with the new L1 mechanics and tooling matures to fork an L1.
When `weight != 0`, the weight of the validator is updated to `weight` and `minNonce` is updated to `nonce + 1`.
When `weight == 0`, the validator is removed from the validator set. All state related to the validator, including the `minNonce` and `validationID`, are reaped from the P-Chain state. Tracking these post-removal is not required since `validationID` can never be re-initialized due to the replay protection provided by `expiry` in `RegisterL1ValidatorTx`. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that `RemainingBalanceOwner` is specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
Note: There is no explicit `EndTime` for L1 validators added in a `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`. The only time when L1 validators are removed from the L1's validator set is through this transaction when `weight == 0`.
#### `DisableL1ValidatorTx`
L1 validators can use `DisableL1ValidatorTx` to mark their validator as inactive. The specification of this transaction is:
```go
type DisableL1ValidatorTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Authorizes this validator to be disabled
DisableAuth verify.Verifiable `json:"disableAuthorization"`
}
```
The `DisableOwner` specified for this validator must sign the transaction. Any unspent \$AVAX in the validator's `Balance` will be issued in a single UTXO to the `RemainingBalanceOwner` for this validator. Recall that both `DisableOwner` and `RemainingBalanceOwner` are specified when the validator is first added to the L1's validator set (in either `ConvertSubnetToL1Tx` or `RegisterL1ValidatorTx`).
For full removal from an L1's validator set, a `SetL1ValidatorWeightTx` must be issued with weight `0`. To do so, a Warp message is required from the L1's validator manager. However, to support the ability to claim the unspent `Balance` for a validator without authorization is critical for failed L1s.
Note that this does not modify an L1's total staking weight. This transaction marks the validator as inactive, but does not remove it from the L1's validator set. Inactive validators can re-activate at any time by increasing their balance with an `IncreaseL1ValidatorBalanceTx`.
L1 creators should be aware that there is no notion of `MinStakeDuration` that is enforced by the P-Chain. It is expected that L1s who choose to enforce a `MinStakeDuration` will lock the validator's Stake for the L1's desired `MinStakeDuration`.
#### `IncreaseL1ValidatorBalanceTx`
L1 validators are required to maintain a non-zero balance used to pay the continuous fee on the P-Chain in order to be considered active. The `IncreaseL1ValidatorBalanceTx` can be used by anybody to add additional \$AVAX to the `Balance` to a validator. The specification of this transaction is:
```go
type IncreaseL1ValidatorBalanceTx struct {
// Metadata, inputs and outputs
BaseTx
// ID corresponding to the validator
ValidationID ids.ID `json:"validationID"`
// Balance <= sum($AVAX inputs) - sum($AVAX outputs) - TxFee
Balance uint64 `json:"balance"`
}
```
If the validator corresponding to `ValidationID` is currently inactive (`Balance` was exhausted or `DisableL1ValidatorTx` was issued), this transaction will move them back to the active validator set.
Note: The \$AVAX added to `Balance` can be claimed at any time by the validator using `DisableL1ValidatorTx`.
### Bootstrapping L1 Nodes
Bootstrapping a node/validator is the process of securely recreating the latest state of the blockchain locally. At the end of this process, the local state of a node/validator must be in sync with the local state of other virtuous nodes/validators. The node/validator can then verify new incoming transactions and reach consensus with other nodes/validators.
To bootstrap a node/validator, a few critical questions must be answered: How does one discover peers in the network? How does one determine that a discovered peer is honestly participating in the network?
For standalone networks like the Avalanche Primary Network, this is done by connecting to a hardcoded [set](https://github.com/ava-labs/avalanchego/blob/master/genesis/bootstrappers.json) of trusted bootstrappers to then discover new peers. Ethereum calls their set [bootnodes](https://ethereum.org/developers/docs/nodes-and-clients/bootnodes).
Since L1 validators are not required to be Primary Network validators, a list of validator IPs to connect to (the functional bootstrappers of the L1) cannot be provided by simply connecting to the Primary Network validators. However, the Primary Network can enable nodes tracking an L1 to seamlessly connect to the validators by tracking and gossiping L1 validator IPs. L1s will not need to operate and maintain a set of bootstrappers and can rely on the Primary Network for peer discovery.
### Sidebar: L1 Sovereignty
After this ACP is activated, the P-Chain will no longer support staking of any assets other than $AVAX for the Primary Network. The P-Chain will not support the distribution of staking rewards for L1s. All staking-related operations for L1 validation must be managed by the L1's validator manager. The P-Chain simply requires a continuous fee per validator. If an L1 would like to manage their validator's balances on the P-Chain, it can cover the cost for all L1 validators by posting the $AVAX balance on the P-Chain. L1s can implement any mechanism they want to pay the continuous fee charged by the P-Chain for its participants.
The L1 has full ownership over its validator set, not the P-Chain. There are no restrictions on what requirements an L1 can have for validators to join. Any stake that is required to join the L1's validator set is not locked on the P-Chain. If a validator is removed from the L1's validator set via a `SetL1ValidatorWeightTx` with weight `0`, the stake will continue to be locked outside of the P-Chain. How each L1 handles stake associated with the validator is entirely left up to the L1 and can be treated independently to what happens on the P-Chain.
The relationship between the P-Chain and L1s provides a dynamic where L1s can use the P-Chain as an impartial judge to modify parameters (in addition to its existing role of helping to validate incoming Avalanche Warp Messages). If a validator is misbehaving, the L1 validators can collectively generate a BLS multisig to reduce the voting weight of a misbehaving validator. This operation is fully secured by the Avalanche Primary Network (225M $AVAX or $8.325B at the time of writing).
Follow-up ACPs could extend the P-Chain \<-> L1 relationship to include parametrization of the 67% threshold to enable L1s to choose a different threshold based on their security model (e.g. a simple majority of 51%).
### Continuous Fee Mechanism
Every additional validator on the P-Chain adds persistent load to the Avalanche Network. When a validator transaction is issued on the P-Chain, it is charged for the computational cost of the transaction itself but is not charged for the cost of an active validator over the time they are validating on the network (which may be indefinitely). This is a common problem in blockchains, spawning many state rent proposals in the broader blockchain space to address it. The following fee mechanism takes advantage of the fact that each L1 validator uses the same amount of computation and charges each L1 validator the dynamic base fee for every discrete unit of time it is active.
To charge each L1 validator, the notion of a `Balance` is introduced. The `Balance` of a validator will be continuously charged during the time they are active to cover the cost of storing the associated validator properties (BLS key, weight, nonce) in memory and to track IPs (in addition to other services provided by the Primary Network). This `Balance` is initialized with the `RegisterL1ValidatorTx` that added them to the active validator set. `Balance` can be increased at any time using the `IncreaseL1ValidatorBalanceTx`. When this `Balance` reaches `0`, the validator will be considered "inactive" and will no longer participate in validating the L1. Inactive validators can be moved back to the active validator set at any time using the same `IncreaseL1ValidatorBalanceTx`. Once a validator is considered inactive, the P-Chain will remove these properties from memory and only retain them on disk. All messages from that validator will be considered invalid until it is revived using the `IncreaseL1ValidatorBalanceTx`. L1s can reduce the amount of inactive weight by removing inactive validators with the `SetL1ValidatorWeightTx` (`Weight` = 0).
Since each L1 validator is charged the same amount at each point in time, tracking the fees for the entire validator set is straight-forward. The accumulated dynamic base fee for the entire network is tracked in a single uint. This accumulated value should be equal to the fee charged if a validator was active from the time the accumulator was instantiated. The validator set is maintained in a priority queue. A pseudocode implementation of the continuous fee mechanism is provided below.
```python
# Pseudocode
class ValidatorQueue:
def __init__(self, fee_getter):
self.acc = 0
self.queue = PriorityQueue()
self.fee_getter = fee_getter
# At each time period, increment the accumulator and
# pop all validators from the top of the queue that
# ran out of funds.
# Note: The amount of work done in a single block
# should be bounded to prevent a large number of
# validator operations from happening at the same
# time.
def time_elapse(self, t):
self.acc = self.acc + self.fee_getter(t)
while True:
vdr = self.queue.peek()
if vdr.balance < self.acc:
self.queue.pop()
continue
return
# Validator was added
def validator_enter(self, vdr):
vdr.balance = vdr.balance + self.acc
self.queue.add(vdr)
# Validator was removed
def validator_remove(self, vdrNodeID):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance - self.acc
vdr.refund() # Refund [vdr.balance] to [RemainingBalanceOwner]
self.queue.remove()
# Validator's balance was topped up
def validator_increase(self, vdrNodeID, balance):
vdr = find_and_remove(self.queue, vdrNodeID)
vdr.balance = vdr.balance + balance
self.queue.add(vdr)
```
#### Fee Algorithm
[ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) proposes a dynamic fee mechanism for transactions on the P-Chain. This mechanism is repurposed with minor modifications for the active L1 validator continuous fee.
At activation, the number of excess active L1 validators $x$ is set to `0`.
The fee rate per second for an active L1 validator is:
$M \cdot \exp\left(\frac{x}{K}\right)$
Where:
* $M$ is the minimum price for an active L1 validator
* $\exp\left(x\right)$ is an approximation of $e^x$ following the EIP-4844 specification
```python
# Approximates factor * e ** (numerator / denominator) using Taylor expansion
def fake_exponential(factor: int, numerator: int, denominator: int) -> int:
i = 1
output = 0
numerator_accum = factor * denominator
while numerator_accum > 0:
output += numerator_accum
numerator_accum = (numerator_accum * numerator) // (denominator * i)
i += 1
return output // denominator
```
* $K$ is a constant to control the rate of change for the L1 validator price
After every second, $x$ will be updated:
$x = \max(x + (V - T), 0)$
Where:
* $V$ is the number of active L1 validators
* $T$ is the target number of active L1 validators
Whenever $x$ increases by $K$, the price per active L1 validator increases by a factor of `~2.7`. If the price per active L1 validator gets too expensive, some active L1 validators will exit the active validator set, decreasing $x$, dropping the price. The price per active L1 validator constantly adjusts to make sure that, on average, the P-Chain has no more than $T$ active L1 validators.
#### Block Processing
Before processing the transactions inside a block, all validators that no longer have a sufficient (non-zero) balance are deactivated.
After processing the transactions inside a block, all validators that do not have a sufficient balance for the next second are deactivated.
##### Block Timestamp Validity Change
To ensure that validators are charged accurately, blocks are only considered valid if advancing the chain times would not cause a validator to have a negative balance.
This upholds the expectation that the number of L1 validators remains constant between blocks.
The block building protocol is modified to account for this change by first checking if the wall clock time removes any validator due to a lack of funds. If the wall clock time does not remove any L1 validators, the wall clock time is used to build the block. If it does, the time at which the first validator gets removed is used.
##### Fee Calculation
The total validator fee assessed in $\Delta t$ is:
```python
# Calculate the fee to charge over Δt
def cost_over_time(V:int, T:int, x:int, Δt: int) -> int:
cost = 0
for _ in range(Δt):
x = max(x + V - T, 0)
cost += fake_exponential(M, x, K)
return cost
```
#### Parameters
The parameters at activation are:
| Parameter | Definition | Value |
| --------- | ------------------------------------------- | ---------------- |
| $T$ | target number of validators | 10\_000 |
| $C$ | capacity number of validators | 20\_000 |
| $M$ | minimum fee rate | 512 nAVAX/s |
| $K$ | constant to control the rate of fee changes | 1\_246\_488\_515 |
An $M$ of 512 nAVAX/s equates to \~1.33 AVAX/month to run an L1 validator, so long as the total number of continuous-fee-paying L1 validators stays at or below $T$.
$K$ was chosen to set the maximum fee doubling rate to \~24 hours. This is in the extreme case that the network has $C$ validators for prolonged periods of time; if the network has $T$+1 validators for example, the fee rate would double every \~27 years.
A future ACP can adjust the parameters to increase $T$, reduce $M$, and/or modify $K$.
#### User Experience
L1 validators are continuously charged a fee, albeit a small one. This poses a challenge for L1 validators: How do they maintain the balance over time?
Node clients should expose an API to track how much balance is remaining in the validator's account. This will provide a way for L1 validators to track how quickly it is going down and top-up when needed. A nice byproduct of the above design is the balance in the validator's account is claimable. This means users can top-up as much \$AVAX as they want and rest-assured knowing they can always retrieve it if there is an excessive amount.
The expectation is that most users will not interact with node clients or track when or how much they need to top-up their validator account. Wallet providers will abstract away most of this process. For users who desire more convenience, L1-as-a-Service providers will abstract away all of this process.
## Backwards Compatibility
This new design for Subnets proposes a large rework to all L1-related mechanics. Rollout should be done on a going-forward basis to not cause any service disruption for live Subnets. All current Subnet validators will be able to continue validating both the Primary Network and whatever Subnets they are validating.
Any state execution changes must be coordinated through a mandatory upgrade. Implementors must take care to continue to verify the existing ruleset until the upgrade is activated. After activation, nodes should verify the new ruleset. Implementors must take care to only verify the presence of 2000 \$AVAX prior to activation.
### Deactivated Transactions
* P-Chain
* `TransformSubnetTx`
After this ACP is activated, Elastic Subnets will be disabled. `TransformSubnetTx` will not be accepted post-activation. As there are no Mainnet Elastic Subnets, there should be no production impact with this deactivation.
### New Transactions
* P-Chain
* `ConvertSubnetToL1Tx`
* `RegisterL1ValidatorTx`
* `SetL1ValidatorWeightTx`
* `DisableL1ValidatorTx`
* `IncreaseL1ValidatorBalanceTx`
## Reference Implementation
ACP-77 was implemented and will be merged into AvalancheGo behind the `Etna` upgrade flag. The full body of work can be found tagged with the `acp77` label [here](https://github.com/ava-labs/avalanchego/issues?q=sort%3Aupdated-desc+label%3Aacp77).
Since Etna is not yet activated, all new transactions introduced in ACP-77 will be rejected by AvalancheGo. If any modifications are made to ACP-77 as part of the ACP process, the implementation must be updated prior to activation.
## Security Considerations
This ACP introduces Avalanche Layer 1s, a new network type that costs significantly less than Avalanche Subnets. This can lead to a large increase in the number of networks and, by extension, the number of validators. Each additional validator adds consistent RAM usage to the P-Chain. However, this should be appropriately metered by the continuous fee mechanism outlined above.
With the sovereignty L1s have from the P-Chain, L1 staking tokens are not locked on the P-Chain. This poses a security consideration for L1 validators: Malicious chains can choose to remove validators at will and take any funds that the validator has locked on the L1. The P-Chain only provides the guarantee that L1 validators can retrieve the remaining \$AVAX Balance for their validator via a `DisableL1ValidatorTx`. Any assets on the L1 is entirely under the purview of the L1. The onus is on L1 validators to vet the L1's security for any assets transferred onto the L1.
With a long window of expiry (24 hours) for the Warp message in `RegisterL1ValidatorTx`, spam of validator registration could lead to high memory pressure on the P-Chain. A future ACP can reduce the window of expiry if 24 hours proves to be a problem.
NodeIDs can be added to an L1's validator set involuntarily. However, it is important to note that any stake/rewards are *not* at risk. For a node operator who was added to a validator set involuntarily, they would only need to generate a new NodeID via key rotation as there is no lock-up of any stake to create a NodeID. This is an explicit tradeoff for easier on-boarding of NodeIDs. This mirrors the Primary Network validators guarantee of no stake/rewards at risk.
The continuous fee mechanism outlined above does not apply to inactive L1 validators since they are not stored in memory. However, inactive L1 validators are persisted on disk which can lead to persistent P-Chain state growth. A future ACP can introduce a mechanism to decrease the rate of P-Chain state growth or provide a state expiry path to reduce the amount of P-Chain state.
## Acknowledgements
Special thanks to [@StephenButtolph](https://github.com/StephenButtolph), [@aaronbuchwald](https://github.com/aaronbuchwald), and [@patrick-ogrady](https://github.com/patrick-ogrady) for their feedback on these ideas. Thank you to the broader Ava Labs Platform Engineering Group for their feedback on this ACP prior to publication.
## Copyright
Copyright and related rights waived via [CC0](https://creativecommons.org/publicdomain/zero/1.0/).
# ACP-83: Dynamic Multidimensional Fees
URL: /docs/acps/83-dynamic-multidimensional-fees
Details for Avalanche Community Proposal 83: Dynamic Multidimensional Fees
| ACP | 83 |
| :---------------- | :------------------------------------------------------------------------------------------------ |
| **Title** | Dynamic multidimensional fees for P-chain and X-chain |
| **Author(s)** | Alberto Benegiamo ([@abi87](https://github.com/abi87)) |
| **Status** | Stale |
| **Track** | Standards |
| **Superseded-By** | [ACP-103](https://github.com/avalanche-foundation/ACPs/blob/main/ACPs/103-dynamic-fees/README.md) |
## Abstract
Introduce a dynamic and multidimensional fees scheme for the P-chain and X-chain.
Dynamic fees helps to preserve the stability of the chain as it provides a feedback mechanism that increases the cost of resources when the network operates above its target utilization.
Multidimensional fees ensures that high demand for orthogonal resources does not drive up the price of underutilized resources. For example, networks provide and consume orthogonal resources including, but not limited to, bandwidth, chain state, read/write throughput, and CPU. By independently metering each resource, they can be granularly priced and stay closer to optimal resource utilization.
## Motivation
The P-Chain and X-Chain currently have fixed fees and in some cases those fees are fixed to zero.
This makes transaction issuance predictable, but does not provide feedback mechanism to preserve chain stability under high load. In contrast, the C-Chain, which has the highest and most regular load among the chains on the Primary Network, already supports dynamic fees. This ACP proposes to introduce a similar dynamic fee mechanism for the P-Chain and X-Chain to further improve the Primary Network's stability and resilience under load.
However, unlike the C-Chain, we propose a multidimensional fee scheme with an exponential update rule for each fee dimension. The [HyperSDK](https://github.com/ava-labs/hypersdk) already utilizes a multidimensional fee scheme with optional priority fees and its efficiency is backed by [academic research](https://arxiv.org/abs/2208.07919).
Finally, we split the fee into two parts: a `base fee` and a `priority fee`. The `base fee` is calculated by the network each block to accurately price each resource at a given point in time. Whatever amount greater than the base fee is burnt is treated as the `priority fee` to prioritize faster transaction inclusion.
## Specification
We introduce the multidimensional scheme first and then how to apply the dynamic fee update rule for each fee dimension. Finally we list the new block verification rules, valid once the new fee scheme activates.
### Multidimensional scheme components
We define four fee dimensions, `Bandwidth`, `Reads`, `Writes`, `Compute`, to describe transactions complexity. In more details:
* `Bandwidth` measures the transaction size in bytes, as encoded by the AvalancheGo codec. Byte length is a proxy for the network resources needed to disseminate the transaction.
* `Reads` measures the number of DB reads needed to verify the transactions. DB reads include UTXOs reads and any other state quantity relevant for the specific transaction.
* `Writes` measures the number of DB writes following the transaction verification. DB writes include UTXOs generated as outputs of the transactions and any other state quantity relevant for the specific transaction.
* `Compute` measures the number of signatures to be verified, including UTXOs ones and those related to authorization of specific operations.
For each fee dimension $i$, we define:
* *fee rate* $r_i$ as the price, denominated in AVAX, to be paid for a transaction with complexity $u_i$ along the fee dimension $i$.
* *base fee* as the minimal fee needed to accept a transaction. Base fee is given be the formula
$base \ fee = \sum_{i=0}^3 r_i \times u_i$
* *priority fee* as an optional fee paid on top of the base fee to speed up the transaction inclusion in a block.
### Dynamic scheme components
Fee rates are updated in time, to allow a fee increase when network is getting congested. Each new block is a potential source of congestion, as its transactions carry complexity that each validator must process to verify and eventually accept the block. The more complexity carries a block, and the more rapidly blocks are produced, the higher the congestion.
We seek a scheme that rapidly increases the fees when blocks complexity goes above a defined threshold and that equally rapidly decreases the fees once complexity goes down (because blocks carry less/simpler transactions, or because they are produced more slowly). We define the desired threshold as a *target complexity rate* $T$: we would want to process every second a block whose complexity is $T$. Any complexity more than that causes some congestion that we want to penalize via fees.
In order to update fees rates we track, per each block and each fee dimension, a parameter called cumulative excess complexity. Fee rates applied to a block will be defined in terms of cumulative excess complexity as we show in the following.
Suppose that a block $B_t$ is the current chain tip. $B_t$ has the following features:
* $t$ is its timestamp.
* $\Delta C_t$ is the cumulative excess complexity along fee dimension $i$.
Say a new block $B_{t + \Delta T}$ is built on top of $B$, with the following features:
* $t + \Delta T$ is its timestamp
* $C_{t + \Delta T}$ is its complexity along fee dimension $i$.
Then the fee rate $r_{t + \Delta T}$ applied for the block $B_{t + \Delta T}$ along dimension $i$ will be:
$r_{t + \Delta T} = r^{min} \times e^{\frac{max(0, \Delta C_t - T \times \Delta T)}{Denom}}$
where
* $r^{min}$ is the minimal fee rate along fee dimension $i$
* $T$ is the target complexity rate along fee dimension $i$
* $Denom$ is a normalization constant for the fee dimension $i$
Moreover, once the block $B_{t + \Delta T}$ is accepted, the cumulative excess complexity is updated as follows:
$\Delta C_{t + \Delta T} = max\large(0, \Delta C_{t} - T \times \Delta T\large) + C_{t + \Delta T}$
The fee rate update formula guarantees that fee rates increase if incoming blocks are complex (large $C_{t + \Delta T}$) and if blocks are emitted rapidly (small $\Delta T$). Symmetrically, fee rates decrease to the minimum if incoming blocks are less complex and if blocks are produced less frequently.\
The update formula has a few paramenters to be tuned, independently, for each fee dimension. We defer discussion about tuning to the [implementation section](#tuning-the-update-formula).
## Block verification rules
Upon activation of the dynamic multidimensional fees scheme we modify block processing as follows:
* **Bound block complexity**. For each fee dimension $i$, we define a *maximal block complexity* $Max$. A block is only valid if the block complexity $C$ is less than the maximum block complexity: $C \leq Max$.
* **Verify transaction fee**. When verifying each transaction in a block, we confirm that it can cover its own base fee. Note that both base fee and optional priority fees are burned.
## User Experience
### How will the wallets estimate the fees?
AvalancheGo nodes will provide new APIs exposing the current and expected fee rates, as they are likely to change block by block. Wallets can then use the fees rates to select UTXOs to pay the transaction fees. Moreover, the AvalancheGo implementation proposed above offers a `fees.Calculator` struct that can be reused by wallets and downstream projects to evaluate calculate fees.
### How will wallets be able to re-issue Txs at a higher fee?
Wallets should be able to simply re-issue the transaction since current AvalancheGo implementation drops mempool transactions whose fee rate is lower than current one. More specifically, a transaction may be valid the moment it enters the mempool and it won’t be re-verified as long as it stays in there. However, as soon as the transaction is selected to be included in the next block, it is re-verified against the latest preferred tip. If fees are not enough by this time, the transaction is dropped and the wallet can simply re-issue it at a higher fee, or wait for the fee rate to go down. Note that priority fees offer some buffer space against an increase in the fee rate. A transaction paying just the base fee will be evicted from the mempool in the face of a fee rate increase, while a transaction paying some extra priority fee may have enough buffer room to stay valid after some amount of fee increase.
### How does priority fees guarantee a faster block inclusion?
AvalancheGo mempool will be restructured to order transactions by priority fees. Transactions paying priority fees will be selected for block inclusion first, without violating any spend dependency.
## Backwards Compatibility
Modifying the fee scheme for P-Chain and X-Chain requires a mandatory upgrade for activation. Moreover, wallets must be modified to properly handle the new fee scheme once activated.
## Reference Implementation
The implementation is split across multiple PRs:
* P-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2707](https://github.com/ava-labs/avalanchego/issues/2707)
* X-Chain work is tracked in this issue: [https://github.com/ava-labs/avalanchego/issues/2708](https://github.com/ava-labs/avalanchego/issues/2708)
A very important implementation step is tuning the update formula parameters for each chain and each fee dimension. We show here the principles we followed for tuning and a simulation based on historical data.
### Tuning the update formula
The basic idea is to measure the complexity of blocks already accepted and derive the parameters from it. You can find the historical data in [this repo](https://github.com/abi87/complexities).\
To simplify the exposition I am purposefully ignoring chain specifics (like P-chain proposal blocks). We can account for chain specifics while processing the historical data. Here are the principles:
* **Target block complexity rate $T$**: calculate the distribution of block complexity and pick a high enough quantile.
* **Max block complexity $Max$**: this is probably the trickiest parameter to set.
Historically we had [pretty big transactions](https://subnets.avax.network/p-chain/tx/27pjHPRCvd3zaoQUYMesqtkVfZ188uP93zetNSqk3kSH1WjED1) (more than $1.000$ referenced utxos). Setting a max block complexity so high that these big transactions are allowed is akin to setting no complexity cap.
On the other side, we still want to allow, even encourage, UTXO consolidation, so we may want to allow transactions [like this](https://subnets.avax.network/p-chain/tx/2LxyHzbi2AGJ4GAcHXth6pj5DwVLWeVmog2SAfh4WrqSBdENhV).
A principled way to set max block complexity may be the following:
* calculate the target block complexity rate (see previous point)
* calculate the median time elapsed among consecutive blocks
* The product of these two quantities should gives us something like a target block complexity.
* Set the max block complexity to say $\times 50$ the target value.
* **Normalization coefficient $Denom$**: I suggest we size it as follows:
* Find the largest historical peak, i.e. the sequence of consecutive blocks which contained the most complexity in the shortest period of time
* Tune $Denom$ so that it would cause a $\times 10000$ increase in the fee rate for such a peak. This increase would push fees from the milliAVAX we normally pay under stable network condition up to tens of AVAX.
* **Minimal fee rates $r^{min}$**: we could size them so that transactions fees do not change very much with respect to the currently fixed values.
We simulate below how the update formula would behave on an peak period from Avalanche mainnet.
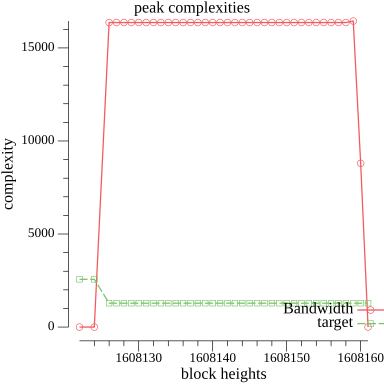 />
/>
 />
/>
- ],
"managerAddresses": [
- ],
"enabledAddresses": [
- ],
}
}
```
`AllowList` configuration affects only the related precompile. For instance, the admin address in `feeManagerConfig` does not affect admin addresses in other activated precompiles.
The `AllowList` solidity interface is defined as follows, and can be found in [IAllowList.sol](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/contracts/contracts/interfaces/IAllowList.sol):
```solidity
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
interface IAllowList {
event RoleSet(
uint256 indexed role,
address indexed account,
address indexed sender,
uint256 oldRole
);
// Set [addr] to have the admin role over the precompile contract.
function setAdmin(address addr) external;
// Set [addr] to be enabled on the precompile contract.
function setEnabled(address addr) external;
// Set [addr] to have the manager role over the precompile contract.
function setManager(address addr) external;
// Set [addr] to have no role for the precompile contract.
function setNone(address addr) external;
// Read the status of [addr].
function readAllowList(address addr) external view returns (uint256 role);
}
```
`readAllowList(addr)` will return a uint256 with a value of 0, 1, or 2, corresponding to the roles `None`, `Enabled`, and `Admin` respectively.
`RoleSet` is an event that is emitted when a role is set for an address. It includes the role, the modified address, the sender as indexed parameters and the old role as non-indexed parameter. Events in precompiles are activated after Durango upgrade.
Note: `AllowList` is not an actual contract but just an interface. It's not callable by itself. This is used by other precompiles. Check other precompile sections to see how this works.
### Restricting Smart Contract Deployers[](#restricting-smart-contract-deployers "Direct link to heading")
If you'd like to restrict who has the ability to deploy contracts on your Avalanche L1, you can provide an `AllowList` configuration in your genesis or upgrade file:
```json
{
"contractDeployerAllowListConfig": {
"blockTimestamp": 0,
"adminAddresses": ["0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC"]
}
}
```
In this example, `0x8db97C7cEcE249c2b98bDC0226Cc4C2A57BF52FC` is named as the `Admin` of the `ContractDeployerAllowList`. This enables it to add other `Admin` or to add `Enabled` addresses. Both `Admin` and `Enabled` can deploy contracts. To provide a great UX with factory contracts, the `tx.Origin` is checked for being a valid deployer instead of the caller of `CREATE`. This means that factory contracts will still be able to create new contracts as long as the sender of the original transaction is an allow listed deployer.
The `Stateful Precompile` contract powering the `ContractDeployerAllowList` adheres to the [AllowList Solidity interface](#allowlist-interface) at `0x0200000000000000000000000000000000000000` (you can load this interface and interact directly in Remix):
* If you attempt to add a `Enabled` and you are not an `Admin`, you will see something like: 
* If you attempt to deploy a contract but you are not an `Admin` not a `Enabled`, you will see something like: 
* If you call `readAllowList(addr)` then you can read the current role of `addr`, which will return a uint256 with a value of 0, 1, or 2, corresponding to the roles `None`, `Enabled`, and `Admin` respectively.
- ],
"managerAddresses": [
- ],
"enabledAddresses": [
- ],
}
}
```
## Non-Strict Mode[](#non-strict-mode "Direct link to heading")
Strict mode unpacking prevents using extra padded bytes in inputs. This created some issue in few legacy contracts like Gnosis Multisig wallet. For more information about strict mode see [solidity docs](https://docs.soliditylang.org/en/latest/abi-spec.html#strict-encoding-mode).
For Hello world example we were using this `UnpackSetGreetingInput` with strict mode enabled before:
```go
func UnpackSetGreetingInput(input []byte) (string, error) {
// This function was using strict mode unpacking by default.
res, err := HelloWorldABI.UnpackInput("setGreeting", input)
if err != nil {
return "", err
}
unpacked := *abi.ConvertType(res[0], new(string)).(*string)
return unpacked, nil
}
```
In order to handle extra padded bytes, Subnet-EVM will start using non-strict mode with Durango in `Input Unpackers`. However since this change will be non-backward compatible you need to ensure that this will only be activated after the Durango network upgrade.
You can use the `contract.IsDurangoActivated` function to check if the Durango network upgrade is activated. Now we will using this function to start using non-strict mode unpacking:
```go
// UnpackSetGreetingInput attempts to unpack [input] into the string type argument
// assumes that [input] does not include selector (omits first 4 func signature bytes)
// if [useStrictMode] is true, it will return an error if the length of [input] is not [common.HashLength]
func UnpackSetGreetingInput(input []byte, useStrictMode bool) (string, error) {
// Initially we had this check to ensure that the input was the correct length.
// However solidity does not always pack the input to the correct length, and allows
// for extra padding bytes to be added to the end of the input. Therefore, we have removed
// this check with the Durango. We still need to keep this check for backwards compatibility.
if useStrictMode && len(input) > common.HashLength {
return "", ErrInputExceedsLimit
}
res, err := HelloWorldABI.UnpackInput("setGreeting", input, useStrictMode)
if err != nil {
return "", err
}
unpacked := *abi.ConvertType(res[0], new(string)).(*string)
return unpacked, nil
}
```
To call this function in `setGreeting` we should use Durango activation as follows [here](https://github.com/ava-labs/subnet-evm/blob/helloworld-official-tutorial-v2/precompile/contracts/helloworld/contract.go#L159-L167):
```go
// do not use strict mode after Durango
useStrictMode := !contract.IsDurangoActivated(accessibleState)
// attempts to unpack [input] into the arguments to the SetGreetingInput.
// Assumes that [input] does not include selector
// You can use unpacked [inputStruct] variable in your code
inputStruct, err := UnpackSetGreetingInput(input, useStrictMode)
if err != nil {
return nil, remainingGas, err
}
```
This will ensure that non-strict mode unpacking is used after Durango activation.
This should not impose any critical issue for your custom precompiles. If you want to keep using the old strict mode and keep the backward compatibility you can use `true` for the `useStrictMode` parameter.
However if your precompile is mainly used from other deployed contracts (Solidity) you should do this transition in order to increase the compatibility of your precompile.
# Add Validator
URL: /docs/avalanche-l1s/validator-manager/add-validator
Learn how to add validators to your Avalanche L1 blockchain.
### Register a Validator
Validator registration is initiated with a call to `initializeValidatorRegistration`. The sender of this transaction is registered as the validator owner. Churn limitations are checked - only a certain (configurable) percentage of the total weight is allowed to be added or removed in a (configurable) period of time. The `ValidatorManager` then constructs a `RegisterL1ValidatorMessage` Warp message to be sent to the P-Chain. Each validator registration request includes all of the information needed to identify the validator and its stake weight, as well as an `expiry` timestamp before which the `RegisterL1ValidatorMessage` must be delivered to the P-Chain. If the validator is not registered on the P-Chain before the `expiry`, then the validator may be removed from the contract state by calling `completeEndValidation`.
The `RegisterL1ValidatorMessage` is delivered to the P-Chain as the Warp message payload of a `RegisterL1ValidatorTx`. Please see the transaction specification for validity requirements. The P-Chain then signs a `L1ValidatorRegistrationMessage` Warp message indicating that the specified validator was successfully registered on the P-Chain.
The `L1ValidatorRegistrationMessage` is delivered to the `ValidatorManager` via a call to `completeValidatorRegistration`. For PoS Validator Managers, staking rewards begin accruing at this time.
### (PoS only) Register a Delegator
`PoSValidatorManager` supports delegation to an actively staked validator as a way for users to earn staking rewards without having to validate the chain. Delegators pay a configurable percentage fee on any earned staking rewards to the host validator. A delegator may be registered by calling `initializeDelegatorRegistration` and providing an amount to stake. The delegator will be registered as long as churn restrictions are not violated. The delegator is reflected on the P-Chain by adjusting the validator's registered weight via a `SetL1ValidatorWeightTx`. The weight change acknowledgement is delivered to the `PoSValidatorManager` via an `L1ValidatorWeightMessage`, which is provided by calling `completeDelegatorRegistration`.
The P-Chain is only willing to sign an `L1ValidatorWeightMessage` for an active validator. Once a validator exit has been initiated (via a call to `initializeEndValidation`), the `PoSValidatorManager` must assume that the validator has been deactivated on the P-Chain, and will therefore not sign any further weight updates. Therefore, it is invalid to initiate adding or removing a delegator when the validator is in this state, though it may be valid to complete an already initiated delegator action, depending on the order of delivery to the P-Chain. If the delegator weight change was submitted (and a Warp signature on the acknowledgement retrieved) before the validator was removed, then the delegator action may be completed. Otherwise, the acknowledgement of the validation end must first be delivered before completing the delegator action.
# Validator Manager Contracts
URL: /docs/avalanche-l1s/validator-manager/contract
This page lists all available contracts for the Validator Manager.
# Validator Manager Contracts
The contracts in this directory define the Validator Manager used to manage Avalanche L1 validators, as defined in [ACP-77](https://github.com/avalanche-foundation/ACPs/tree/main/ACPs/77-reinventing-subnets). They comply with [ACP-99](https://github.com/avalanche-foundation/ACPs/tree/main/ACPs/99-validatorsetmanager-contract), which specifies the standard minimal functionality that Validator Managers should implement. The contracts in this directory are are related as follows: